

들어가며
드디어 !
우리 팀이 운영하는 서비스가 2026년 2월 10일 기준 회원 수 500명을 돌파했다. 🎉
그동안 미뤄왔던 이벤트를 이제는 정말 해볼 수 있겠다는 생각이 들었다.
“유저가 어느 정도 모이고, 보여주고 싶은 기능이 갖춰지면 하자”라고 계속 미뤄왔는데, 드디어 그 시점이 온 것이다.
예전부터 꼭 해보고 싶었던 이벤트가 하나 있었다.
바로 선착순 이벤트였다.


내가 참여자 입장에서 여러 이벤트를 보며 늘 아쉬웠던 점이 있었다.
응모형 이벤트는 당첨 과정이 잘 보이지 않다 보니,
가끔은 “정말 주는 건가?” 싶은 순간이 있었다.
그래서 나중에 내가 서비스를 만들게 된다면,
적어도 이벤트만큼은 결과가 더 분명하게 보이는 방식으로 해보고 싶었다.
팀 회의에서도 비슷한 의견이 나왔고, 팀원들 역시 선착순 이벤트에 찬성했다.
그렇게 시작된 것이 봄봄의 첫 이벤트였다.
예산이 넉넉한 편은 아니었지만, 그래도 총 70개의 메가커피 기프티콘을 상품으로 준비했다.
예상 참여 인원은 대략 1,000명 정도로 잡았다.
문제는 선착순 이벤트가 생각보다 단순하지 않았다는 점이다.
짧은 시간에 요청이 한꺼번에 몰릴 가능성이 높았고, 여기에 새로고침이나 재시도까지 겹치면 순간 트래픽은 예상 참여 인원보다 훨씬 커질 수 있었다.
게다가 봄봄은 웹도 지원하고 있었기 때문에, 여러 개의 탭을 띄워 거의 동시에 시도하는 경우도 고려해야 했다.
실제로 선착순 이벤트를 할 때 탭을 2~3개 열어두고 동시에 시도하는 사람은 꽤 많다.
그래서 최악의 시나리오를 먼저 생각했다.
1,000명 중 80%가 오픈 직후 첫 1~2초 안에 진입한다고 가정하면,
진입 요청만으로도 순간적으로 약 400~800 TPS가 발생한다.
여기에 사용자가 평균 2개의 탭을 띄운다고 가정하면,
순간 트래픽은 약 800~1,600 TPS 수준까지 올라간다.
그리고 실제 운영에서는 재시도, 네트워크 지연, 예상을 벗어난 동시 진입 같은 변수도 충분히 생길 수 있다.
그래서 우리는 어느 정도 여유를 두고, 목표치를 피크 2,000 TPS로 잡았다.
즉 이번 이벤트는 단순한 기능 구현이 아니라,
짧은 순간에 몰리는 대량 요청을 어떻게 안전하게 처리할 것인가까지 함께 풀어야 하는 문제였다.
정리해보면 요구사항은 아래와 같았다.
요구사항
- 선착순 발급 순서 보장
- 목표 TPS 2,000
- 1인당 1개의 쿠폰만 발급 보장
- 이벤트 종료이후 발급 차단
- 발급 성공/실패를 명확히 반환
고민사항
- 순간적인 엄청난 트래픽을 어떻게 감당해낼지?
- 발급 시점에 DB 경합(락/커넥션 고갈)을 어떻게 해결할지
- 분산 환경에서 동시성을 어떻게 잡을지
현재 상태
“지금 구조로는 2000TPS는 절대 못 버틴다”
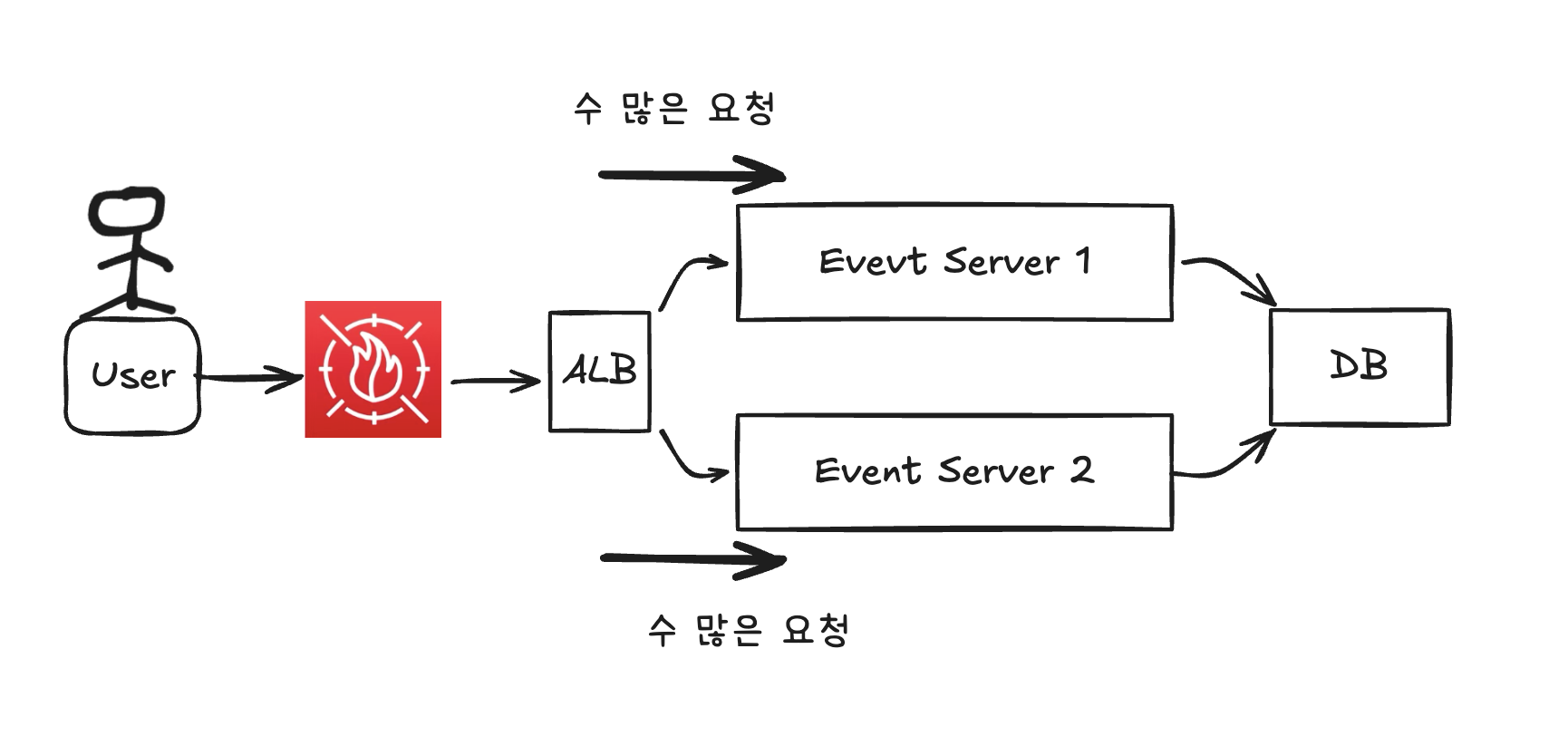
서버를 아키텍처를 아주 간단하게 그리면 아래처럼 분산서버로 되어있다.

문제는 “API 서버가 분산이냐”가 아니라, 순간적으로 수많은 요청이 몰릴 때 시스템이 버티느냐였다.
현재 운영 환경의 피크 TPS는 250 정도 버틸 수 있다.
지금 상태에서 기능만 구현해버리면 서버 스레드/커넥션 풀 대기 증가 → 응답 지연/타임아웃, 이로인한 사용자 경험 붕괴 그리고 최악은… 이벤트 때문에 기존 서비스까지 영향을 받는 것이다.
그래서 어떻게 할지 고민을 많았다.
1차 문제 : 운영서버에 이벤트 로직을?
기존 운영 서버에 이벤트 관련 로직을 넣는게 가장 편하다.
하지만 현재 운영서버에 아무리 설계를 해봐도 운영서버로는 한 번에 수 많은 요청을 처리할 수 없었다.
그렇다고 무작정 스케일 아웃하기에도 비용적 부담도 있었고 혹시라도 예측이 틀려서 기존에 서비스를 사용하는 유저가 이벤트 때문에 이용하지 못하는 경우는 없어야 된다고 생각했다.
1차 해결: 이벤트 서버로 분리
이벤트는 시작 순간에 트래픽이 급격히 몰린다.
따라서 이벤트 트래픽을 운영 서버 API와 분리한 이벤트 서버로 받는 것이 1차적인 안정화 전략이다.
이렇게 해두면 설사 이벤트 서버가 다운되더라도, 기존 서비스 이용은 큰 문제가 없게 된다.
어차피 이벤트 할 때만 서버를 사용하기에 비용적 부담도 적었다.

2차 문제: 제일 먼저 트래픽을 받는 곳은?
이벤트 서버를 분리했다면, 다음 고민은 “이벤트 트래픽의 입구를 어떻게 구성할 것인가” 였다.
선착순 이벤트에서는 애플리케이션 서버 자체도 중요하지만, 그보다 먼저 모든 요청이 처음 도착하는 지점이 과연 수 많은 요청을 받을 수 있는지 확인해야한다.
뒤쪽 이벤트 서버를 여러 대로 늘려 두더라도, 정작 가장 앞단에서 요청을 제대로 받아주지 못하면 그 뒤의 확장성은 아무 의미가 없어지기 때문이다.
여기서 핵심은 트래픽이 얼마나 몰릴지 예측할 수 없는 상황에서 입구를 어떻게 구성할까였다.
그래서 몇 가지 선택지를 두고 비교했다.
방법 1: EC2 인스턴스에 HAProxy를 두고 직접 로드밸런싱하기
가장 먼저 떠오른 선택지는 별도 EC2 인스턴스에 HAProxy 같은 리버스 프록시를 두고,
그 인스턴스가 로드밸런서 역할을 하게 만드는 방식이었다.
이 방식의 장점은 분명하다.
- 익숙한 도구로 빠르게 구성할 수 있있어서 러닝커브가 전혀없다.
- 처음에는 작은 비용으로 시작하기 쉽다.
- 세부 튜닝 포인트를 직접 통제할 수 있다.
즉, “작게 시작해보기” 에는 꽤 매력적인 선택지다.
하지만 선착순 이벤트 관점에서는 단점이 훨씬 크게 보였다.
첫째, 로드밸런서 역할을 하는 인스턴스 자체가 단일 장애 지점 즉, SPOF가 된다.
현재 운영의 로드밸런서를 담당하는 인스턴스는 t4g.nano이다.
물론 해당 스펙을 가지고 그대로 이벤트 서버에도 적용할 수는 없다.
그런다고 스펙을 올린다면 버틸 수는 있을 것 같다.
하지만 그건 어디까지나 더 큰 단일 인스턴스가 되는 것에 가깝다.
트래픽이 예측 범위를 넘는 순간, 병목은 뒤쪽 서버가 아니라 입구 인스턴스 하나에 집중될 수 있다.
물론 Route 53의 failover 라우팅을 사용하면 장애 시 다른 대상으로 우회시키는 구성은 가능하다.
또는 Auto Scaling을 통해 장애가 난 로드밸런서 인스턴스를 새 인스턴스로 교체하도록 만들 수도 있다.
하지만 이 방식들은 선착순 이벤트의 “첫 관문”을 맡기기에는 한계가 있었다.
Auto Scaling 기반 교체는 새 인스턴스가 기동되고 서비스 가능 상태가 되기까지 수 분이 걸릴 수 있고,
Route 53 failover는 DNS 기반 전환이기 때문에 캐시와 전파 지연의 영향을 받는다.
즉, 둘 다 장애 복구 수단 으로는 의미가 있지만,
짧은 순간에 대량 요청이 몰리는 선착순 이벤트에서 입구를 즉시 안정적으로 유지하는 방식 으로 보기는 어려웠다.
둘째, 운영 부담이 직접 생긴다.
커넥션 수, 커널 파라미터, 헬스체크, 장애 복구, 인스턴스 교체 같은 문제를 전부 스스로 챙겨야 한다.
평소 트래픽이 안정적이라면 괜찮지만, 선착순 이벤트처럼 짧은 시간에 요청이 급격히 몰릴 수 있는 상황 에서는 이 부담이 꽤 크게 느껴졌다 , 즉 이 방식은 비용과 단순함 면에서는 장점이 있지만, 예상치 못한 트래픽에서 가장 앞단을 직접 운영해야 한다는 점에서 구조적인 리스크가 컸다.
방법 2: NLB(Network Load Balancer)
두 번째로 고려해본 건 AWS의 관리형 로드밸런서인 NLB이다.
NLB는 L4 계층에서 동작하고, AWS 공식 문서에서도 급격하고 변동성 큰 트래픽 패턴에 최적화되어 있다고 안내한다.
또 AZ별 static IP를 제공할 수 있고, 매우 낮은 지연 시간과 높은 처리량이 강점이다.
이 특성만 보면, “순간적으로 몰리는 이벤트 트래픽”과 잘 맞아 보인다.
실제로 초고성능 TCP 처리나 정적 IP가 중요한 환경이라면 굉장히 좋은 선택지다.
다만 이번에는 몇 가지 이유로 최종 선택에서는 밀렸다.
우리에게 더 중요했던 건 단순한 L4 전달 성능만이 아니라,
- HTTP 레벨에서 다루기 쉬운 운영성
- 웹 애플리케이션 앞단으로서의 관리 편의성
- WAF 연동 같은 보안 구성
- 타깃 상태를 보고 빠르게 제외/복구시키는 흐름
같은 요소들이었다.
특히 AWS WAF는 대표적으로 CloudFront, API Gateway, 그리고 Application Load Balancer 와 연동되는 서비스로 안내된다. 이번 이벤트는 웹 요청을 받는 구조였기 때문에, 순수한 연결 레벨 처리보다 애플리케이션 레벨에서 다루기 쉬운 선택 이 더 적합하다고 판단했다.
즉, NLB는 성능 면에서는 매우 강력하지만,
이번 문제에서는 “가장 앞단의 웹 트래픽 운영”이라는 목적과 완전히 일치하지는 않았다.
방버 3: ALB(Application Load Balancer)
ALB는 애플리케이션 계층(L7)에서 동작하고,
AWS 문서 기준으로 트래픽 변화에 따라 자동으로 확장되며,
헬스 체크를 통해 정상 타깃에만 요청을 전달할 수 있다.
또한 타깃은 유연하게 추가/제거할 수 있다.
게다가 ELB 계열은 멀티 AZ 구성이 가능하고, AWS에서도 둘 이상의 AZ에 걸쳐 운영하는 구성을 권장하는 흐름을 확인할 수 있다.
이런 점은 앞단의 가용성을 높이는 데 유리하다.
ALB의 장점은 이번 이벤트 상황과 잘 맞았다.
- 앞단을 관리형으로 둘 수 있다.
- 특정 이벤트 서버가 비정상이면 헬스 체크 기반으로 자동 제외할 수 있다.
- 트래픽 증가를 직접 프록시 인스턴스 한 대로 받아내는 구조보다 안전하다.
- WAF 연동이 자연스럽다.
물론 ALB에도 단점은 있다.
- 직접 프록시를 운영하는 것보다 비용이 더 들 수 있다.
- L4 중심의 극단적인 성능 최적화나 static IP 같은 요구사항에서는 NLB가 더 잘 맞을 수 있다.
- 로드밸런서 동작을 세밀하게 직접 제어하는 자유도는 self-managed 프록시보다 낮다.
그럼에도 이번에는 이 단점보다 장점이 더 컸다.
우리가 정말 피하고 싶었던 것은
이벤트 트래픽의 가장 첫 번째 관문을 단일 인스턴스로 직접 책임지는 상황이었기 때문이다.
2차 문제 해결: ALB로 결정!
정리하면 판단 기준은 이랬다.
HAProxy를 EC2에 직접 올리는 방식은
작고 빠르게 시작하기엔 좋지만,
입구 자체가 단일 병목이 되기 쉽고 운영 부담이 모두 우리에게 남는다.
NLB는 급격한 트래픽과 고성능 연결 처리에는 매우 강력하지만,
이번처럼 웹 애플리케이션 앞단에서 운영성과 보안 연동까지 함께 고려하는 상황 에서는 다소 결이 달랐다.
반면 ALB는 트래픽 변화 대응, 헬스 체크 기반 타깃 제외, 멀티 AZ 구성, WAF 연동이라는 측면에서
“입구를 안전하게 관리형으로 넘긴다” 는 목적에 가장 잘 맞았다.
결국 이번 선택의 핵심은
“ALB가 무조건 최고라서”가 아니라,
트래픽 규모를 정확히 예측할 수 없는 선착순 이벤트에서 가장 위험한 단일 병목을 제거하는 것이 우선이었기 때문 이다.
입구는 관리형으로 안정성을 확보하고, 우리는 뒤쪽 이벤트 서버의 오토스케일링, 큐 처리, 재고 차감 같은
서비스 핵심 문제에 집중하는 편이 전체 시스템 관점에서 더 합리적이라고 판단했다.
여기까지 하면 서버 형태는 아래와 같아진다.

3차 문제: 로드밸런서 뒤의 서버는 얼마나 받아낼 수 있을까
자 그럼 ALB까지는 무사히 들어왔다.
그 다음으로 마주해야 할 곳은 서버다.
ALB는 요청을 여러 서버로 분산시켜 줄 수 있지만,
정작 그 뒤에 있는 각 서버가 그 요청을 제대로 받아낼 수 있는 상태인지 는 또 다른 문제였다.
만약 서버가 2대라면 각 서버는 1,000 TPS씩 감당해야한다.
1,000 TPS를 받기 위해 과연 아무런 준비를 하지 않아도 될까??
아니다
선착순 이벤트에서 중요한 건 단순히 요청을 여러 대로 나누는 것이 아니다.
짧은 시간에 많은 요청이 몰릴 때, 각 서버가 웹 서버 레벨에서 연결을 받아들이고, 요청을 큐잉하고, 애플리케이션 스레드로 넘겨 처리할 수 있어야 한다.
앞단에서 분산이 잘 되어도, 뒤쪽 서버가 그 요청을 받아내지 못하면 병목은 단지 위치만 바뀔 뿐이다.
그래서 이 단계에서는 DB 같은 하위 시스템까지 한 번에 보지 않았다.
그건 다음 문제로 넘기고, 먼저 더 앞단의 질문부터 풀고 싶었다.
“이벤트 서버 한 대는, 애플리케이션 서버 자체만 놓고 봤을 때 얼마나 많은 요청을 안정적으로 받아낼 수 있는까?”
평소라면 크게 고민할 필요가 없다.
대략적으로 계산해도, 현재 우리가 겪는 소규모 트래픽보다 훨씬 많은 요청을 서버가 감당할 수 있기 때문이다.
하지만 이번 이벤트는 다르다.
짧은 시간에 많은 요청이 몰릴 것으로 예상되는 만큼, 서버가 어디까지 버틸 수 있는지 대략적인 한계는 미리 알고 있어야 했다.
그래야 이 정도 트래픽은 서버 단까지는 큰 문제 없이 받아낼 수 있겠구나라는 판단을 할 수 있기 때문이다.
1. OS단 설정
일단 서버 관점에서 보면, 인스턴스의 운영체제는 리눅스다.
외부에서 들어온 요청은 곧바로 애플리케이션으로 전달되는 것이 아니라, 먼저 운영체제가 연결을 받아들이고 소켓 형태로 관리한다.
이때 소켓 역시 파일 디스크립터로 취급되기 때문에, 동시에 많은 연결이 몰릴 수 있는 환경이라면 nofile 같은 운영체제 한도도 함께 확인해야 한다.
또한 순간적으로 연결이 몰릴 수 있으므로 `somaxconn`, `tcp_max_syn_backlog` 같은 `backlog` 관련 설정도 같이 점검했다.
1) nofile
우선 ulimit -n 명령어는 현재 셸에서 열 수 있는 파일 디스크립터의 최대 개수를 확인하는 명령어다.
ulimit -n
리눅스 환경에서 모든 네트워크 소켓은 파일 디스크립터로 관리되므로, 대량의 동시 연결이 발생하는 선착순 이벤트 특성상 nofile 한도 점검은 필수적이었다. AWS Linux 2023의 기본값인 65,535는 16비트 시스템의 전통적인 상한값으로, 본 시스템에서 설정한 톰캣 maxConnections = 10,000를 상회하는 충분한 여유 수치였다. 따라서 하위 인프라의 파일 디스크립터 한도보다는 실제 연결 성립의 병목이었던 커널 대기열 최적화에 집중하는 것이 더 합리적인 우선순위라고 판단했다.
왜 65535가 기본값일까?
이 부분은 AWS 공식 문서에서 직접적인 설명을 찾지는 못했다.
65535는 2의 16제곱에서 1을 뺀 값(16비트 최대값)이라, 옛날부터 포트 번호 개수, 각종 커널/네트워크 한도 등에서 많이 쓰이던 전통적인 상한 값이라고 한다. 그래서 운영체제나 네트워크 관련 기본 한도에서도 종종 보이는 숫자라고 이해하면 된다.
2) backlog 관련 설정

요청이 서버에 들어온다고 해서 곧바로 애플리케이션이 처리하는 것은 아니다.
그 전에 리눅스 커널이 먼저 연결을 받고, 잠깐 줄을 세워두는 구간이 있다.
이걸 놀이공원 입장 줄에 비유해보면 이해가 쉽다.
- 문 앞에서 입장 확인을 기다리는 줄
- 입장 확인은 끝났지만, 실제로 안으로 들어가기 전 잠시 대기하는 줄
리눅스는 이런 식으로 연결을 단계별로 잠깐 보관한다.
그리고 이때 중요한 설정이 바로 `tcp_max_syn_backlog`와 `somaxconn`이다.
(1) tcp_max_syn_backlog
이건 아직 연결이 완전히 성립되기 전,
즉 TCP 3-way handshake가 진행 중인 연결들을 얼마나 대기열에 쌓아둘 수 있는지에 대한 값이다.
TCP 연결은 보통 아래 순서로 맺어진다.
- 클라이언트가 SYN을 보낸다.
- 서버가 SYN-ACK를 보낸다.
- 클라이언트가 마지막 ACK를 보내면 연결이 성립된다.
여기서 마지막 ACK가 오기 전까지는
아직 연결이 완전히 끝난 것이 아니라 half-open connection 라고 볼 수 있다.
tcp_max_syn_backlog는 바로 이 반쯤 열린 연결들을 잠깐 담아두는 대기열 크기다.
쉽게 말하면, 이 값은 서버 입장 직전, 문 앞에서 신분 확인을 기다리는 줄의 길이에 가깝다.
이 값이 너무 작으면 짧은 순간에 연결 시도가 몰렸을 때 문제가 생길 수 있다.
아직 연결이 완전히 맺어지지 않은 연결들이 금방 대기열을 채워 버리고,
그 뒤에 들어온 연결들은 재시도되거나 지연될 수 있다.
사용자 입장에서는 이런 식으로 보일 수 있다.
- 접속이 바로 안 됨
- 잠깐 멈춘 것처럼 느껴짐
- 재시도 끝에 겨우 붙음
- 심하면 타임아웃처럼 보임
즉, `tcp_max_syn_backlog`는 연결이 막 시작되는 초반 구간에서 순간적인 몰림을 흡수해 주는 완충 공간이라고 이해하면 좋다.
(2) net.core.somaxconn
이번에는 TCP handshake가 이미 끝난 뒤,
즉 연결은 성립했지만 애플리케이션이 아직 accept() 해서 가져가지 못한 상태에서 사용되는 대기열과 관련 있다.
예를 들어 연결 자체는 이미 성공했는데,
nginx가 아직 꺼내 가지 못했거나
tomcat이 아직 받아 가지 못했거나
애플리케이션이 잠깐 밀리고 있는 상태 라면 커널은 그 연결을 잠시 줄 세워 둔다.
이때 실제 대기열 크기는 애플리케이션이 listen(fd, backlog)로 요청한 값과, 커널의 somaxconn 상한이 함께 작용해 결정된다.
쉽게 설명하면 somaxconn은 그 상한선 역할을 하는 값이라고 보면 된다.
비유하면 이건 입장 확인은 끝났지만, 실제로 안으로 들어가기 전까지 서 있는 안쪽 대기줄이다.
- tcp_max_syn_backlog는 문 앞 대기줄
- somaxconn은 문은 통과했지만 아직 직원이 안으로 안내하기 전 대기줄
애플리케이션은 보통 listen(fd, backlog) 같은 방식으로
"이 정도까지는 대기열을 두고 싶다"는 값을 넘긴다.
하지만 커널은 그 값을 무조건 다 받아주지 않는다.
예를 들어 애플리케이션이 backlog를 10000으로 주더라도, 커널의 somaxconn 값이 4096이라면 실제로는 그보다 크게 잡히지 못한다. 즉, 애플리케이션에서 아무리 크게 설정해도 커널 쪽 상한이 더 낮으면 결국 그 값에 막히게 된다.
정리하면 이렇다.
tcp_max_syn_backlog
- 아직 handshake가 끝나지 않은 연결들의 대기열
- 연결 시작 단계의 버퍼
somaxconn
- handshake는 끝났지만 애플리케이션이 아직 못 받아간 연결의 대기열 상한
- 연결 성립 이후의 버퍼
즉, 요청이 몰릴 때는 단순히 톰캣이나 nginx 설정만 볼 것이 아니라,
그 앞단에서 리눅스 커널이 어디까지 연결을 받아두고 버틸 수 있는지도 함께 봐야 한다.
직접 확인해보고 싶다면 아래 명령어로 현재 서버 값을 볼 수 있다.
sysctl net.core.somaxconn
sysctl net.ipv4.tcp_max_syn_backlog
확인한 AWS Linux 2023 인스턴스에서는 아래와 같은 값으로 설정되어 있었다.

확인 결과, somaxconn = 4096은 우리가 예상한 순간적인 접속 몰림을 기준으로 봤을 때 당장 부족해 보이지는 않았다.
또한 accept-count를 기본값으로 둘 예정이라 실질적으로 영향을 끼치지는 않는다. 다만 만약 accept-count를 크게 올려야 하는 상황이 생겼을 때 OS 상한에 막히지 않도록 조정이 필요하다.
반면 tcp_max_syn_backlog = 128은 선착순 이벤트처럼 아주 짧은 시간에 연결 시도가 몰릴 수 있는 상황에서는 다소 작게 느껴졌다.
somaxconn이 연결 성립 이후의 대기열이라면, tcp_max_syn_backlog는 연결이 완전히 맺어지기 전 단계의 완충 공간에 가깝다.
이번 이벤트에서는 전체 처리량보다도 오픈 직후의 순간적인 몰림이 더 중요하다고 판단했고, 따라서 somaxconn보다는 tcp_max_syn_backlog를 먼저 여유 있게 조정하는 것이 더 필요하다고 봤다.
물론 backlog 관련 설정만으로 모든 문제가 해결되지는 않는다.
애플리케이션이 연결을 충분히 빠르게 받아가지 못하면 병목은 결국 다른 구간에서 다시 생길 수 있다.
그럼에도 이 설정은 적어도 애플리케이션에 도달하기 전, 커널 단계에서 연결이 밀려나는 상황을 줄이기 위한 기본적인 대비라고 생각했다.
2. 톰캣 설정 점검
그다음으로 봐야 할 것은 톰캣 설정과 이벤트 서버의 수용 한계였다.
이 부분을 먼저 살펴본 이유는 단순했다.
설정이 맞지 않으면, 실제 병목은 톰캣이나 연결 처리 구간에 있는데도 인스턴스 성능이 부족한 것처럼 오해할 수 있기 때문이다.
예를 들어 CPU나 메모리는 아직 여유가 있는데도 maxThreads나 acceptCount가 먼저 한계에 도달하면, 겉으로는 서버 스펙이 부족해 보일 수 있다.
하지만 실제 원인은 인스턴스 체급이 아니라 톰캣 설정일 수도 있다.
이 단계에서 알고 싶었던 것은 조금 더 앞단의 질문들이었다.
- 인스턴스 스펙은 어느 정도가 적절한가
- 톰캣의 최대 스레드 수는 몇으로 두는 게 맞는가
- 요청이 몰릴 때 잠시 대기하는 accept queue 는 어느 정도가 적절한가?
- 서버 한 대가 안정적으로 받아낼 수 있는 요청량의 대략적인 상한은 어느 정도인가
궁금했던 것은 결국 하나였다.
“무너지지 않고 받아낼 수 있는 양이 어느 정도인가?”
이게 중요했던 이유는, 선착순 이벤트 초반에는 처리하는 것보다 먼저 받아내는 것 자체가 문제가 될 수 있기 때문이다.
모든 사용자가 거의 같은 시점에 같은 API를 호출하면, 그 순간의 병목은 비즈니스 로직보다 앞단의 연결 수용, 스레드 수, 대기 구간, 메모리 사용량 같은 곳에서 먼저 드러날 수 있다.
그래서 이 단계에서는 범위를 의도적으로 애플리케이션 서버 자체로 좁혀 보려고 했다.
1) 인스턴스 체급
가장 먼저 본 것은 인스턴스 체급이었다.
너무 작은 인스턴스는 테스트 초반에는 버텨 보일 수 있다.
하지만 요청이 몰리는 순간 CPU, 메모리, 네트워크 처리 여유가 빠르게 줄어들 수 있다.
반대로 무조건 큰 인스턴스를 선택하는 것도 좋은 답은 아니라고 생각했다.
비용은 높아지는데, 실제 병목이 톰캣 설정이나 연결 처리 구간이라면 기대한 만큼의 효과가 나오지 않을 수 있기 때문이다.
즉, 트래픽을 아무리 받아도 리소스가 남아 돌면 비용부담만 커질뿐이다.
그래서 중요한 것은 “무조건 큰 인스턴스” 가 아니라,
“이벤트 서버 역할에 맞는 최소한의 체급이 어디인가” 를 찾는 것이었다.
일단 기준점으로는 t4g.small로 잡고 조정해나갈 생각이다.
2) 톰캣 스레드 설정
그다음으로 중요한 건 톰캣이었다.
서버는 결국 톰캣을 통해 요청을 받아 애플리케이션으로 넘긴다.
이때 maxThreads가 너무 작으면 요청이 빠르게 대기 상태로 밀리고, 응답 시간도 급격히 늘어날 수 있다.
그렇다고 무작정 스레드를 늘리는 것도 정답은 아니다.
스레드 수가 지나치게 많아지면 문맥 전환 비용이 커지고, 메모리 사용량도 늘어나며, 오히려 처리 효율이 떨어질 수 있다.
즉, 톰캣 설정은 “많을수록 좋다”가 아니라
인스턴스 자원과 요청 특성에 맞는 적정값을 찾는 문제 였다.
3) 연결 수와 대기 구간
선착순 이벤트에서는 짧은 시간에 연결이 몰릴 수 있다.
이 경우 서버가 실제 비즈니스 로직을 실행하기도 전에, 연결 수용 단계나 요청 대기 구간에서 먼저 압박이 생길 수 있다.
Tomcat 기준으로 보면 maxThreads는 실제 요청 처리에 투입될 수 있는 작업 스레드 수에 가깝고, maxConnections는 동시에 유지할 수 있는 연결 수의 상한, acceptCount는 처리 여력을 넘긴 연결이 잠시 대기하는 구간과 관련된 값이다.
즉, 얼마나 처리할 수 있는지, 얼마나 받아둘 수 있는지, 순간적으로 얼마나 버텨줄 수 있는지는 서로 다른 문제였다.
이 값을 너무 작게 잡으면 순간적으로 몰리는 트래픽을 흡수하지 못한다.
연결 수 한도에 빠르게 도달하고 대기 구간도 금방 차 버리면, 일부 요청은 애플리케이션까지 도달하지도 못한 채 거절되거나 타임아웃처럼 보일 수 있다.
앞단에 ALB가 있어 요청을 잘 분산하더라도, 뒤쪽 서버가 연결 자체를 받아내지 못하면 사용자는 결국 “접속이 안 된다”라고 느끼게 된다.
반대로 값을 너무 크게 잡는다고 해서 무조건 좋은 것도 아니었다.
처리 가능한 수준보다 훨씬 많은 연결을 오래 붙잡아 두면, 실패가 빨리 드러나는 대신 지연이 서버 내부에 쌓이게 된다.초반에는 버티는 것처럼 보일 수 있지만, 어느 순간부터 응답 시간이 급격히 증가하고 전체 처리 효율도 오히려 떨어질 수 있다.
그래서 중요한 것은 단순히 값을 크게 늘리는 것이 아니라,
어느 시점부터 연결이 쌓이기 시작하는지,
어느 순간부터 응답 시간이 갑자기 증가하는지,
그리고 그 지연이 일시적인 버스트 흡수인지, 아니면 병목의 시작인지를 구분해서 보는 것이 더 중요하다고 생각했다.
다만 이 지점의 정확한 한계는 애플리케이션 서버만 보고 단정하기 어려웠다.
실제 서비스에서는 후단 DB까지 포함한 전체 처리 경로가 함께 영향을 주기 때문이다.
그래서 이 단계에서는 이런 위험이 존재한다는 점을 먼저 인지하고, 구체적인 병목 지점과 임계치는 다음 단계에서 DB를 포함한 부하 테스트를 통해 확인하기로 했다.
4) 무엇이 먼저 한계에 도달하는지
서버 한계는 단순히 CPU 사용률 하나로 설명되지 않는다.
어떤 경우에는 CPU가 먼저 치솟을 수 있고, 어떤 경우에는 메모리 사용량이나 GC 부담이 먼저 문제를 일으킬 수도 있다.
또 어떤 경우에는 톰캣 스레드 풀이 먼저 포화되거나, 연결 수와 대기 구간이 먼저 압박을 받을 수도 있다.
그래서 “지금 인스턴스가 버티는가”만 보는 것으로는 부족하다고 생각했다.
무엇 때문에 버티지 못하는가까지 같이 봐야, 스레드를 조정할지, 인스턴스 스펙을 올릴지, 서버 수를 늘릴지를 판단할 수 있기 때문이다.
3차 문제의 잠정 판단
결론부터 말하면, 이 단계에서 정답이 되는 설정값을 한 번에 확정할 수는 없었다.
인스턴스 체급, 톰캣 설정, 그리고 후단 DB까지 모든 요소가 유기적으로 연결되어 있기 때문이다. 문서나 감에 의존하기보다, 명확한 기준점을 먼저 잡고 부하 테스트를 통해 수치를 깎아 나가는 방식이 더 합리적이라 판단했다.
일단 첫 기준 인스턴스는 t4g.small로 잡았다.
톰캣 설정도 이 기준점 위에서 잠정적으로 아래와 같이 시작해보기로 했다.
- maxThreads = 150
- accept-count = 300
- max-connections = 10000
maxThreads는 150으로 잡았다.
t4g.small은 vCPU가 2개다. 톰캣의 기본값은 200이지만, vCPU 2개 위에서 200개의 스레드가 동시에 활성화되면 컨텍스트 스위칭 비용이 커지고, 오히려 처리 효율이 떨어질 수 있다. 이번 이벤트의 핵심 로직은 Redis 조회 → 상태 판단 → 응답 반환으로, CPU를 오래 점유하는 무거운 연산이 아니라 I/O 대기가 주를 이루는 가벼운 흐름이었다. 이런 구조에서는 스레드를 무작정 늘리기보다, 한정된 CPU 위에서 문맥 전환 비용을 억제하면서 가벼운 요청을 빠르게 회전시키는 쪽이 더 유리하다고 봤다. 기본값 200에서 조금 줄여 150을 기준점으로 잡되, 부하 테스트에서 스레드 풀이 먼저 포화되는지 CPU가 먼저 한계에 도달하는지를 보고 조정할 계획이었다.
accept-count는 건드리지 않았다.
accept-count는 톰캣이 서버 소켓을 만들 때 OS에 전달하는 listen backlog 값이다. 쉽게 말하면 OS 레벨에서 잠시 연결을 줄 세워 둘 수 있는 대기 공간의 크기다.
뒤에서 설명할 max-connections와의 관계를 먼저 정리하면 이렇다. 새 연결이 도착하면 OS가 TCP handshake를 처리하고, 톰캣의 Acceptor 스레드가 그 연결을 accept()해서 NIO Selector에 등록한다. 이 시점부터 해당 연결은 max-connections에 카운트된다. 그리고 스레드가 다 바쁜 상태에서 새 요청이 들어와도, NIO 안에서 스레드가 빌 때까지 대기할 수 있다. 스레드 없이도 연결을 가볍게 유지할 수 있는 것이 NIO의 장점이다.
그렇다면 accept-count가 의미를 갖을 때는 max-connections가 꽉 찼을 때다.
max-connections 한도에 도달하면 톰캣은 accept()를 멈추고, 그 이후에 도착하는 연결은 OS backlog, 즉 accept-count 큐에서 대기하게 된다. 이 큐마저 차면 OS가 연결 자체를 거부하고, 사용자는 "접속이 안 된다"고 느끼게 된다.
정리하면 연결 거부까지의 흐름은 이렇다.
- max-connections에 여유가 있으면 → 연결은 정상적으로 accept()되고, 스레드가 바쁘더라도 NIO 안에서 대기
- max-connections가 꽉 차면 → 새 연결은 accept-count 큐에서 대기
- accept-count마저 차면 → OS가 연결을 거부
즉, accept-count는 평소에 사용되는 큐가 아니라 max-connections가 한계에 도달한 극단적인 상황에서의 마지막 완충 장치에 가깝다.
이번 이벤트에서 이 값을 조정할 필요가 있는지를 생각해봤다.
결론부터 말하면 기본값을 유지하기로 했다.
우리의 max-connections는 5,000이고, 예상 동시 연결은 약 2,000~3,000 수준이다. 즉, 정상 시나리오에서는 max-connections에 충분한 여유가 있기 때문에 accept-count 큐가 사용될 일이 거의 없다.
만약 동시 연결이 5,000을 넘어서 이 큐까지 사용되는 상황이라면, 이미 예상 트래픽을 한참 벗어난 비정상 상태다. 그 시점에서 100건을 더 받아주든 300건을 더 받아주든 상황이 크게 달라지지 않는다. 오히려 빠르게 거절해서 사용자가 "지금은 접속이 어렵다"는 피드백을 빨리 받는 편이, OS 레벨에서 응답 없이 오래 기다리는 것보다 나은 경험이라고 봤다.
결국 중요한 것은 모든 설정을 무조건 건드리는 것이 아니라, 조정할 근거가 있는 값만 건드리는 것이라고 생각했다. accept-count는 조정할 근거가 없었고, 부하 테스트에서 이 구간이 실제로 문제가 된다면 그때 조정해도 늦지 않다고 판단했다.
max-connections는 5,000으로 잡았다.
먼저 max-connections가 뭔지부터 정리하면, 이 값은 톰캣이 동시에 열어둘 수 있는 TCP 연결의 최대 개수다.
여기서 중요한 건 "열어둘 수 있는"이라는 표현이다. 연결이 열려 있다고 해서 그 연결이 지금 당장 처리되고 있다는 뜻은 아니다.
Spring Boot의 톰캣은 기본적으로 NIO(Non-blocking I/O) 커넥터를 사용한다. NIO 방식에서는 연결 하나가 스레드 하나를 계속 점유하지 않는다. 대신 selector라는 구조가 여러 연결을 관리하다가, 실제로 데이터를 읽거나 쓸 준비가 된 연결만 스레드에 넘겨준다. 즉, 처리 중이 아닌 유휴 연결은 스레드를 잡아먹지 않고 가볍게 유지된다. 그래서 max-connections를 maxThreads보다 훨씬 크게 잡아도 CPU나 메모리 부담이 바로 늘어나지는 않는다.
예상 참여 인원 1,000명이 평균 2~3개의 탭을 열면 동시 TCP 연결은 약 2,000~3,000개 수준이다. 이 연결들은 대기열 상태 조회 폴링이 이어지는 동안 keep-alive로 유지되므로, 이벤트가 진행되는 수 분간 연결이 쌓인 채 유지될 수 있다. 여기에 예상을 벗어난 재시도나 네트워크 지연으로 연결이 예상보다 오래 남아 있는 경우까지 감안해, 약 2배의 여유를 두어 5,000으로 잡았다.
톰캣의 기본값은 8,192다. 기본값보다 오히려 낮게 잡은 셈인데, 이건 의도적인 판단이었다. 무작정 높게 잡기보다는 예상 트래픽에 근거한 값을 기준으로 두고, 부하 테스트에서 실제로 동시 연결이 어디까지 올라가는지를 확인한 뒤 조정하는 쪽이 더 낫다고 봤다. NIO 기반이라 유휴 연결의 부담은 크지 않지만, 그렇다고 근거 없이 큰 수를 넣어두면 나중에 병목이 생겼을 때 이 값이 원인인지 아닌지를 구분하기가 어려워지기 때문이다.
물론 연결을 많이 열어둔다고 처리가 빨라지는 것은 아니다. 실제 처리 속도를 결정하는 것은 여전히 maxThreads다. 다만 앞단에서 연결이 거부되어 요청이 아예 도달하지 못하는 상황보다는, 일단 연결은 받아두고 그 안에서 스레드가 순서대로 처리하는 흐름이 이번 이벤트에는 더 적합하다고 봤다.
4차 문제: DB 병목

서버를 여러개로 대비한다고 해도 이벤트 요청이 결국 같은 DB로 향한다면,
병목은 사라진 게 아니라 위치만 바뀐 셈이다.
우리의 DB는 하나였고, 사양도 AWS RDS t4g.micro 수준이었다.
이 스펙에서는 사용할 수 있는 커넥션 수에도 분명한 한계가 있었다.
예를들어 RDS t4g.micro로 한다면 최대 커넥션이 83개 수준이다.
그 이상으로 늘리는 것은 현실적으로 어렵다.
무리하게 확장하려 해도 메모리 부담이 커지고, 작은 인스턴스 특성상 안정적으로 버티기 힘들다.
겉으로 보기엔 83개면 적지 않아 보일 수 있다.
하지만 선착순 이벤트처럼 여러 서버가 동시에 같은 DB를 바라보는 상황에서는 이야기가 달라진다.
서버 한 대당 커넥션 풀을 기본값인 10개로만 잡아도 서버 2대면 20개 서버 3대면 30개 서버 4대면 40개 정도다.
즉, 이벤트 서버를 여러 대로 늘리더라도
DB 입장에서 동시에 처리할 수 있는 요청 수는 결국 이 커넥션 수에 의해 제한된다.
여기서 더 큰 문제는 처리하지 못한 요청이 그냥 사라지는 것이 아니라, 전부 애플리케이션 서버 안에서 대기하게 된다는 점이다.
이벤트 시작과 동시에 2천명이 동시에 요청을 보낸다고 가정해보자.
이벤트 서버를 4대로 늘렸다고 해도,
동시에 DB 작업을 수행할 수 있는 요청 수는 극히 적다.
그보다 많은 요청은 DB에 도달하지도 못한 채 커넥션을 기다리게 된다.
문제는 이 순간부터다.
DB가 병목이 되는 순간, 단순히 “조금 느려지는 것”으로 끝나지 않는다.
서버 내부에서는 연쇄적으로 장애가 퍼지기 시작한다.
첫 번째로, 스레드가 반환되지 못하고 점점 쌓인다.
DB 커넥션을 얻지 못한 요청은 작업을 끝내지 못한 채 계속 대기한다.
대기 중인 요청 하나하나는 스레드, 메모리, 소켓 같은 자원을 붙잡고 있고,
이 수가 많아질수록 서버는 점점 새로운 요청을 받을 여유를 잃어간다.
두 번째로, 대기열이 DB가 아니라 애플리케이션 서버 내부에 생긴다.
우리가 원한 것은 “DB가 천천히 처리하는 것”이 아니라
“DB 앞에서 질서 있게 제어하는 것”이었는데,
아무 장치 없이 DB로 바로 보내는 구조에서는 그 대기열이 전부 서버 내부에 쌓인다.
이건 굉장히 좋지 않은 신호다.
대기 중인 수천개의 요청은 스레드 점유 힙/네이티브, 메모리 증가, 커넥션 대기 증가, GC 부담 증가
로 이어지고, 결국 서버 전체를 무겁게 만든다.
세 번째로, 타임아웃이 나기 시작한다.
커넥션을 오래 기다리던 요청은 결국 timeout에 걸리고,
사용자는 502, 504 같은 차가운 에러 페이지를 마주하게 된다.
하지만 문제는 여기서 끝나지 않는다.
선착순 이벤트에서 사용자는 에러를 보면 그냥 떠나지 않는다.
대부분은 새로고침을 하거나 다시 시도한다.
즉, DB가 느려진다, 요청이 서버에 쌓인다, 타임아웃이 난다, 사용자가 재시도한다, 요청이 더 몰린다
는 식의 악순환이 만들어진다.
이벤트 서버를 늘리는 것만으로는 부족했다.
서버를 늘릴수록 앞단은 더 많은 요청을 받을 수 있게 되지만,
그 요청이 모두 같은 DB로 향하는 순간 병목은 더 선명해질 뿐이었다.
문제는 “서버가 몇 대냐”가 아니라,그 많은 요청을 DB까지 그대로 보내도 되느냐였다.
그리고 답은 명확했다.
그대로 보내면 안 된다.
DB는 최종 확정만 책임지게 하고, 그 앞에서 트래픽을 흡수하고 순서를 정리해 줄 완충 구간이 필요했다.
문제 해결 시도 1: DB 동시성 제어
처음에는 당연히 DB 안에서 해결하는 방법들을 떠올렸다.
비관적 락, 낙관적 락, 스킵 락, 조건부 업데이트 같은 방법들이다.
이 방식들은 분명 의미가 있다.
실제로 같은 재고를 여러 요청이 동시에 건드릴 때, 정합성을 지키기 위해 자주 사용하는 방법이기도 하다.
하지만 여기서 중요한 건
이 기법들은 데이터 정합성을 지키는 데는 강하지만, 폭주하는 트래픽을 막아내는 근본적인 해결책은 아니라는 것이다.
예를 들어 비관적 락은 안전하다.
대신 동시에 몰리는 요청이 많아질수록 기다리는 요청도 함께 늘어난다.
하나의 요청이 락을 쥐고 있는 동안 수십, 수백 개의 요청이 DB 커넥션을 붙잡고 대기하게 되는데, 이는 결국 커넥션 풀 고갈과 시스템 전체의 응답 지연으로 이어진다.
정합성을 지키려다 서비스 전체가 멈추는 셈이다.
낙관적 락은 락을 오래 잡지 않아 가볍지만, 충돌이 많아지면 실패와 재시도가 급격히 늘어난다. 선착순처럼 같은 자원에 경쟁이 집중되는 상황에서는 적합하지 않는 방법이다.
스킵 락은 여러 작업자가 병렬로 작업을 나눠 처리할 때 유용하지만, 그 전에 이미 요청이 DB까지 쏟아지고 있다는 사실 자체는 바꾸지 못한다.
즉, 이 기법들은
DB에 들어온 요청을 어떻게 안전하게 처리할 것인가에 대한 답이지,
DB로 너무 많은 요청이 한꺼번에 몰리는 상황 자체를 어떻게 막을 것인가에 대한 답은 아니었다.
여기서 문제의 본질이 더 선명해졌다.
우리가 막아야 했던 것은
“같은 row를 동시에 수정하는 문제” 이전에,
수많은 요청이 동시에 DB 앞에 몰려드는 상황 그 자체였다.
DB는 마지막에 정합성을 보장하는 곳으로는 적합하다.
하지만 이벤트 시작 순간의 폭주를 정면으로 받아내는 곳으로 쓰기에는 너무 비싸고, 너무 무겁고, 너무 느렸다.
그래서 DB를 정면으로 방패 삼는 구조 대신, DB 앞단에서 들어오는 폭발적인 트래픽을 흡수하는 구조로 생각을 바꾸게 됐다.
문제 해결 시도 2: 메모리 기반 저장소 도입
DB 앞단에서 트래픽을 흡수할 완충 지대를 찾기 위해, 자연스럽게 메모리 기반 저장소를 떠올리게 됐다.
다만 이때 필요한 것은 단순히 “빠른 캐시”가 아니었다.
먼저 들어온 순서를 매기고, 같은 사용자의 중복 참여를 막고, 현재 상태를 저장하고, 필요하면 여러 조건을 한 번에 처리할 수 있어야 했다.
당시 기준에서 후보는 크게 세 가지였다.
첫 번째는 Memcached였다.
Memcached는 매우 빠른 인메모리 key-value 저장소이고, 원래도 DB 부하를 줄이기 위한 캐시 용도로 널리 쓰인다. 장점은 단순하고 가볍다는 점이다. 대신 기본 성격이 어디까지나 단순한 key-value 캐시에 가깝기 때문에, 선착순 이벤트처럼 순서를 매기고 상태를 저장하고 중복 참여를 막아야 하는 문제에는 상대적으로 표현력이 부족했다.
두 번째는 Apache Ignite 같은 계열이었다.
Ignite는 단순 캐시라기보다, 메모리 우선 구조 위에 분산 SQL, ACID 트랜잭션, 지속성까지 함께 제공하는 분산 데이터 플랫폼에 가깝다. 대규모 분산 처리나 더 복합적인 데이터 처리 문제를 다루기에는 분명 강력한 선택지다. 다만 이번 이벤트에서 우리에게 필요한 것은 거대한 분산 데이터 플랫폼이라기보다, 짧은 시간 안에 빠르게 검증하고 운영할 수 있는 비교적 단순한 구조였다.
세 번째는 Redis 계열이었다.
Redis는 string, hash, list, set, sorted set, stream 같은 다양한 자료구조를 제공한다. 여기에 Lua Script를 이용하면 여러 연산을 서버 안에서 원자적으로 묶어 처리할 수도 있다. 단순 캐시를 넘어 순서, 상태, 중복 방지, 큐잉 같은 요구사항을 함께 다루기 좋은 쪽이었다.
이렇게 놓고 보니 기준은 분명해졌다.
Memcached를 선택했다면 결국 “순서”, “중복 방지”, “상태” 같은 개념을 애플리케이션 코드에서 더 많이 다시 만들어야 했을 것이다.
반면 Redis는 필요한 개념을 자료구조 수준에서 어느 정도 바로 제공해 주기 때문에, 문제를 더 자연스럽게 모델링할 수 있었다.
또 Redis는 명령 단위 처리 자체가 단순하고 빠른 편이고, 필요하다면 이후에 여러 연산을 서버 안에서 묶어 처리하는 방향도 열려 있었다.
이 시점에서는 아직 최종 원자적 처리 방식을 확정한 것은 아니었지만, 적어도 그런 방향으로 확장할 수 있는 선택지라는 점도 중요했다.
무엇보다도 Redis는 문제를 자료구조 수준에서 비교적 자연스럽게 표현할 수 있었고, 단순 캐시를 넘어 상태 관리 계층으로 쓰기에도 무리가 적었으며, 복잡한 분산 플랫폼까지 들고 오지 않아도 될 만큼 구조가 적절히 가벼웠다
여기에 더해 Redis는 현업에서도 워낙 널리 쓰이고 있었고, 참고할 수 있는 사례와 자료도 가장 풍부했다.
처음 도입하는 입장에서는 새로운 기술을 실험하는 것보다, 이미 많이 검증된 선택지를 가져가는 편이 훨씬 안전했다.
그래서 Redis를 선택하게 됐다.
문제 해결 시도 3: 원자적 연산을 향한 고민
Redis를 도입하고 나서 처음 떠올린 건 매우 단순한 방식이었다.
요청이 들어올 때마다 번호를 하나씩 증가시키고, 그 값이 정해진 수량 이내라면 성공으로 처리하면 되지 않을까?
피크 2,000 TPS를 목표로 잡은 상황에서, 가장 먼저 눈에 들어온 것은 Redis의 INCR 였다.
Redis는 명령을 순차적으로 처리하고, INCR 자체도 원자적으로 동작한다.
즉, 요청이 들어올 때마다 번호를 하나씩 증가시키고, 그 값이 발급 수량 이내라면 성공으로 처리하는 구조를 생각할 수 있었다.
예를 들어 쿠폰이 70개라면,
- 첫 번째 요청은 1번
- 두 번째 요청은 2번
- 70번째 요청까지는 성공
- 71번째 요청부터는 실패
이 구조는 처음엔 꽤 매력적으로 보였다.
Redis는 빠르고, INCR 같은 원자적 연산도 지원하고, 구현도 단순하게 가져갈 수 있기 때문이다.
하지만 구현하다 보니 놓친점이 있었다.
번호를 하나 올리는 것과, 실제 발급을 확정하는 것은 전혀 다른 문제였다.
실제 발급 과정에서는 이런 조건들이 함께 따라온다.
- 이미 참여한 사용자는 아닌지
- 이벤트가 이미 종료된 것은 아닌지
- 재고가 아직 남아 있는지
- 발급 이력을 어떻게 남길지
- 최종적으로 성공 상태를 어떻게 확정할지
문제는 INCR 가 보장해주는 것은 어디까지나 숫자를 하나 증가시키는 것뿐이라는 점이었다.
번호를 올리는 것 자체는 원자적이지만, 그 번호를 바탕으로 실제 발급을 확정하는 과정은 그 뒤에 따로 이어진다.
여기서 문제가 발생한다.
INCR 자체는 원자적이다.
하지만 INCR 결과를 받아와서 애플리케이션 서버가
“이 번호면 발급 가능하네”라고 판단하고
그다음에 중복 확인, 상태 변경, 저장 같은 실제 발급 로직을 수행하는 구조라면
그 사이에는 아주 짧은 틈이 생긴다.
이게 바로 전형적인 Check-Then-Act 문제다.
평소에는 별문제 없어 보일 수 있다.
하지만 선착순 이벤트처럼 많은 요청이 동시에 몰리는 상황에서는, 이 짧은 틈이 그대로 레이스 컨디션으로 이어진다.
예를 들어 여러 서버가 거의 동시에 INCR 결과를 받아 “발급 가능하다”고 판단했다고 해보자.
그다음 단계에서 중복 확인이나 상태 변경이 분리되어 있다면, 그 찰나의 순간에 여러 요청이 동시에 같은 자원을 통과할 수 있다.
결과적으로 중복 발급이나 초과 발급 같은 정합성 문제가 발생할 수 있다.
즉, 번호를 정확히 매기는 것만으로는 부족했다.
정말 필요한 것은
번호 증가, 조건 확인, 상태 변경이 하나의 원자적 단위로 움직이는 구조였다.
분산 락 vs Lua Script
이 문제를 해결하는 방법으로 분산 락을 떠올릴 수 있다.
실제로 여러 서버가 동시에 같은 자원을 다루는 상황에서는 분산 락이 꽤 익숙한 선택지이기도 하다.
하지만 이번 상황에서는 분산 락이 꼭 좋은 선택만은 아니었다.
가장 큰 이유는 비용 대비 효과였다.
분산 락을 쓰려면 보통 락을 잡고, 확인하고, 해제하는 여러 단계가 필요하다.
이 과정은 결국 네트워크 왕복을 여러 번 발생시키고, 락 만료 시간이나 해제 주체 같은 세부 설계까지 함께 고민해야 한다.
2,000 TPS처럼 짧은 순간에 요청이 몰리는 상황에서는, 이 추가 비용 자체가 부담이 될 수 있었다.
반면 우리가 하려던 작업은 생각보다 짧고 명확했다.
- 중복 참여를 확인하고
- 현재 재고를 확인하고
- 가능하면 카운터를 증가시키고
- 상태를 바꾸는 것
이 정도의 짧은 로직이라면, 락을 외부에서 관리하기보다 Redis 내부에서 한 번에 실행하는 편이 더 단순하고 빠르다고 판단했다.
그래서 선택한 것이 Lua Script였다.
Redis는 Lua Script가 실행되는 동안 다른 명령이 중간에 끼어들지 않도록 보장한다.
즉, 여러 명령을 나눠 호출하는 대신, 하나의 스크립트 안에서 한 번에 처리할 수 있다.
이 방식의 장점은 분명했다.
첫째, 진짜로 묶고 싶은 구간을 하나의 원자적 작업으로 만들 수 있다.
중복 확인, 재고 체크, 번호 증가, 상태 변경을 한 번에 처리할 수 있다.
둘째, 네트워크 왕복 횟수를 줄일 수 있다.
애플리케이션 서버가 Redis와 여러 번 통신하며 판단하는 대신, 필요한 명령을 Redis 내부에서 바로 수행하게 만들 수 있다.
셋째, 로직의 책임이 더 분명해진다.
발급 가능 여부를 애플리케이션 서버가 분산해서 판단하는 것이 아니라, Redis 안에서 한 번에 판정하게 되므로 흐름이 더 단단해진다.
결국 중요한 건 단순한 카운팅이 아니었다.
발급 가능 여부를 안전하게 판단하는 것이었다.
그래서 Lua Script 안에서는 이런 흐름을 한 번에 처리하도록 생각했다.
- 이미 발급된 사용자인지 확인한다
- 현재 재고가 남아 있는지 확인한다
- 조건을 만족하면 카운터를 증가시킨다
- 해당 사용자를 발급된 사용자 집합에 기록한다
- 성공/실패 결과를 반환한다
핵심은 같다.
중복 확인 → 재고 확인 → 상태 변경
이 흐름을 더 이상 애플리케이션 서버에서 나눠 처리하지 않고,
Redis 안에서 한 번에 끝내도록 만든 것이다.
다만 여기서 한 가지는 분명히 구분해야 했다.
Lua Script가 보장해주는 원자성은 스크립트 실행 중 다른 Redis 명령이 끼어들지 않는다는 의미의 원자성이다.
즉, 애플리케이션 서버에서 여러 번 나눠 호출할 때 생기던 레이스 컨디션을 줄이는 데는 매우 효과적이다.
다만 이것이 SQL 트랜잭션처럼 자동 롤백까지 보장해주는 것은 아니다.
그래서 스크립트는 최대한 짧고 단순하게 유지해야 했다.
오류가 날 여지가 적은 명령만 넣고, Redis 안에서 오래 실행되는 무거운 로직은 피해야 했다.
Lua Script가 강력한 이유는복잡한 로직을 다 때려 넣을 수 있어서가 아니라,
짧고 명확한 임계 구간을 안전하게 묶을 수 있어서라는 점을 분명히 인식하게 됐다.
문제 해결 시도 4 : Redis를 최종 저장소로?
Lua Script까지 고려하고 나니, 적어도 Redis 안에서 발급 판단을 꽤 안전하게 처리할 수는 있어 보였다.
하지만 여기서 또 다른 고민이 생겼다.
판단을 Redis에서 할 수 있다는 것과, 최종 발급 사실까지 Redis가 책임져도 되는가는 같은 문제인가?
선착순 이벤트에서 정말 중요한 것은
카운터가 몇까지 올라갔는지가 아니라,
최종적으로 누구에게 발급이 확정되었는지가 흔들리지 않게 남는 것이었다.
물론 Redis에도 스냅샷, 복제 같은 보완 장치는 있다.
하지만 그렇다고 해서 Redis만으로 최종 발급 사실까지 모두 책임지게 두는 구조는 적어도 선착순 이벤트에서는 위험하다고 생각했다.
예를 들어 주기적으로 DB에 반영하는 구조를 생각할 수도 있다.
하지만 3초마다 반영하든, 1초마다 반영하든, 그 사이 장애가 발생하면 마지막 반영 구간의 데이터는 유실될 수 있다.
이 공백은 단순한 데이터 손실 문제가 아니라, 잘못하면 누가 실제 당첨자인가가 흔들릴 수 있는 문제였다.
그렇다면 발급이 확정될 때마다 메시지 큐를 통해 DB에 저장하면 되지 않을까?
구조만 놓고 보면 꽤 그럴듯했다.
실제로 몇몇 테크 기업 블로그를 보면 메시큐를 활용한 모습을 자주 목격할 수 있다.
- Redis는 빠르게 경쟁을 처리하고
- 메시지 큐는 발급 이벤트를 안전하게 넘기고
- DB는 최종 발급 내역을 영속적으로 기록한다
하지만 이 방식도 고민할수록 간단하지 않았다.
메시지 큐는 DB를 보호하는 데는 효과적이지만 운영 복잡도와 러닝커브가 엄청났다.

- producer와 consumer를 설계해야 하고
- 메시지 중복 처리도 고려해야 하고
- 재시도 정책도 정해야 하고
- 장애 복구 흐름도 설계해야 하고
- 적재는 성공했지만 응답은 실패한 경우 같은 애매한 상황도 다뤄야 한다
구조는 더 단단해질 수 있지만, 함께 감당해야 할 설계와 운영의 무게는 엄청나게 커진다.
개념적으로는 아주 얕게만 알고 있어 짧은 기간 안에 실제 운영 관점까지 고려해 운영할 수 없다고 판단했다.
또한 러닝커브도 엄청나기에 더더욱 판단에 확신이 들었다.
메시지 큐까지 도입하는 것은, 당시 상황에서는 오버엔지니어링에 가까웠다.
그래서 빠르게 포기했다.
4차 문제 해결 : 대기열
5차 문제 : Redis 안에서 줄 세우기
이제 Redis를 대기열로 쓰기로 했으니 어떤식으로 줄을 세울지를 정하면된다.
처음에는 List를 제일 먼저 떠올렸다.
대기열이라고 하면 가장 직관적으로 떠오르는 자료구조가 리스트였기 때문이다.
앞에서 넣고 뒤에서 빼거나, 뒤에 쌓고 앞에서 꺼내는 방식 자체는 딱 줄 서기의 이미지와 잘 맞아 보였다.
하지만 실제 요구사항을 하나씩 대입해보니 생각보다 불편한 점이 많았다.
우리에게 필요한 건 단순히 순서대로 꺼내기만이 아니었다.
- 특정 사용자가 이미 줄에 들어와 있는지 빠르게 확인할 수 있어야 하고
- 사용자가 지금 몇 번째인지도 바로 보여줄 수 있어야 하고
- 중간에 이탈하거나 재시도하는 상황도 다뤄야 했다
리스트는 순서를 유지하는 데는 좋았지만, 사용자가 중복으로 들어있는지 현재 내 순번이 몇 번인지는 알기 어려웠다.
결국 순서는 리스트로 관리하고, 중복 확인은 또 다른 자료구조로 따로 관리해야 하는 식으로 구조가 갈라질 가능성이 높았다.
줄을 세우는 문제를 단순하게 풀고 싶었는데, 오히려 자료구조가 둘 셋으로 흩어질 수 있다는 점이 걸렸다.
Set도 당연히 후보에 올랐다.
중복 방지만 놓고 보면 오히려 List보다 더 매력적이었다.
같은 사용자가 여러 번 요청하더라도 한 번만 들어가게 만들 수 있고, “이미 참여한 사용자인가?” 같은 체크도 훨씬 자연스럽기 때문이다.
문제는 Set에는 순서가 없다는 것이었다.
선착순 이벤트에서 핵심은 결국 “누가 먼저 들어왔는가”인데, Set만으로는 이걸 표현할 수 없다.
즉, 중복 방지는 해결되더라도 선착순의 본질인 순번 관리가 빠져버린다.
결국 Set 역시 단독으로는 부족했고, 또 다른 순서용 자료구조를 옆에 붙여야 했다.
Stream도 후보에서 완전히 배제한 건 아니었다.
오히려 한때는 꽤 진지하게 고민했다.
요청이 들어온 순서대로 append 되고, 소비자 그룹 같은 개념도 있어서 “이벤트를 순서대로 처리한다”는 느낌에는 잘 맞아 보였기 때문이다.
특히 로그처럼 요청 흐름을 쌓아두고 뒤에서 소비하는 구조를 떠올리면 꽤 그럴듯했다.
하지만 이번 문제를 다시 놓고 보니 우리가 원하는 건 단순한 이벤트 로그 저장이 아니었다.
중요한 건 “지금 누가 몇 번째인가”, “이 사용자가 현재 WAITING인지 ACTIVE인지”, “중복 없이 줄을 서게 할 수 있는가” 였다.
즉, 뒤에서 차례대로 소비하는 것만으로는 부족했고, 현재 대기열 상태를 바로 조회하고 제어할 수 있어야 했다.
Stream은 이런 요구를 풀 수는 있겠지만, 지금 우리 문제에 비해 구조가 다소 무겁게 느껴졌다.
이번 이벤트에서는 메시지를 쌓고 소비하는 시스템보다, 현재 대기 중인 줄을 빠르게 관리하는 시스템이 더 중요했다.
결국 하나씩 비교해보니 기준이 분명해졌다.
- List는 순서에는 강하지만 중복 확인과 순번 조회가 불편했고
- Set은 중복 방지에는 강하지만 순서 자체를 표현할 수 없었고
- Stream은 이벤트 흐름을 쌓고 소비하는 데는 좋지만, 이번처럼 현재 대기열의 순번과 상태를 즉시 다루는 문제에는 다소 무거웠다
결국에 도달한 곳은
순서, 중복 방지, 현재 순번 조회를 한 번에 조금 더 자연스럽게 다룰 수 있는 자료구조
바로 Sorted Set이었다.
5차 문제 해결: Sorted Set
우리가 원하는 대기열은 아래와 같았다.
- 먼저 들어온 순서를 유지할 수 있어야 하고
- 같은 사용자가 여러 번 요청해도 중복으로 줄 서지 않아야 하고
- 사용자가 지금 몇 번째인지 빠르게 확인할 수 있어야 하고
- 필요하면 현재 상태와도 자연스럽게 연결할 수 있어야 했다
즉, 필요한 건 값 저장소가 아니라 정렬된 줄 그 자체를 표현할 수 있는 자료구조였다.
그 기준으로 보니 가장 잘 맞는 건 Sorted Set이었다.

Sorted Set은 member 와 score 를 함께 저장한다.
이 구조가 대기열 문제와 잘 맞았던 이유는 단순했다.
사용자 ID를 member 로 넣고, 들어온 순서를 나타내는 값을 score 로 넣으면 Redis 안에서 대기열 자체가 곧 정렬된 줄이 된다.
즉, 별도로 정렬 로직을 돌리지 않아도
Redis가 score 기준으로 항상 순서를 유지해준다.
이게 생각보다 컸다.
List를 쓸 때는 “순서는 유지되지만 중복 확인은 따로”, Set을 쓸 때는 “중복은 막히지만 순서는 따로”처럼 구조가 계속 둘로 갈라질 가능성이 있었다.
반면 Sorted Set은 순서와 중복 제어를 한 번에 더 자연스럽게 다룰 수 있었다.
특히 member 가 사용자 ID이기 때문에, 같은 사용자가 다시 요청했을 때도 대기열 안에 중복으로 여러 번 쌓이지 않게 제어하기가 훨씬 수월했다. 즉, 한 사람이 여러 번 줄 서는 문제를 다루기에도 잘 맞았다.
또 하나 중요했던 건 순번 조회였다.
이번 이벤트에서는 단순히 뒤에서 차례대로 꺼내기만 하면 되는 것이 아니었다.
사용자 입장에서는 “내가 지금 몇 번째인가?”를 확인할 수 있어야 했고,
서버 입장에서도 특정 사용자가 대기열 안에서 어디쯤 있는지를 비교적 빠르게 알아낼 수 있어야 했다.
이 점에서도 Sorted Set은 잘 맞았다.
정렬된 구조를 유지하고 있기 때문에,
“누가 앞에 있는가”뿐 아니라 “내가 몇 번째인가” 같은 정보까지 자연스럽게 연결할 수 있었다.
결국 Sorted Set은 우리가 대기열에 기대했던 핵심 요구사항을 가장 균형 있게 만족시켜주는 자료구조였다.
- 순서를 유지할 수 있고
- 중복 제어와 연결하기 쉽고
- 현재 순번 조회에도 유리하고
- 상태 관리 구조와도 잘 붙는다
즉, 우리가 찾고 있던 것은 큐처럼 보이는 자료구조가 아니라, 선착순 이벤트에 필요한 질서를 계속 유지해주는 자료구조였고,
그 역할에 가장 잘 맞는 것이 Sorted Set이었다.
6차 문제 : 대기열 상태에서 자신의 차례를 어떻게 확인할지
Sorted Set으로 대기열을 만들고, 사용자를 WAITING 상태로 관리하기 시작하자 바로 다음 문제가 따라왔다.
“이제 사용자는 자신의 차례를 어떻게 확인할 것인가?”
대기열은 서버 입장에서는 정리된 줄이지만, 사용자 입장에서는 보이지 않는 줄이다.
사용자는 단순히 “요청이 접수되었다”는 사실만으로는 충분하지 않았다.
지금 내가 여전히 WAITING 상태인지, 아니면 다음 단계로 넘어갈 수 있는지, 가능하다면 현재 순번이 어느 정도인지를 계속 확인할 수 있어야 했다.
즉, 대기열을 만든 순간부터는 단순히 줄을 세우는 문제만 남는 것이 아니었다.
그 줄을 사용자가 어떤 방식으로 조회하게 할 것인가까지 함께 설계해야 했다.
처음에는 이 부분도 꽤 단순하게 볼 수 있었다.
“상태가 바뀌면 서버가 알려주면 되는 것 아닌가?”
“아니면 사용자가 일정 간격으로 물어보게 하면 되지 않을까?”
그런데 이 질문을 조금만 더 깊게 파고들면, 바로 또 다른 문제가 생긴다.
이번 이벤트에서는 대기 사용자가 수백 명 수준이 아니라, 많게는 2,000명 가까이 동시에 줄을 설 수 있다고 보고 있었다.
즉, 상태 조회 방식 하나를 잘못 선택하면, 실제 발급 요청보다 상태 조회 요청이나 연결 유지 비용이 더 큰 부담이 될 수도 있었다.
이 지점에서 상태 조회 방식으로는 크게 세 가지를 검토할 수 있었다.
결국 문제는 단순했다.
“상태를 보여주는 것”도 중요하지만, 그 상태 조회 요청 자체가 또 다른 트래픽 폭탄이 되지 않게 만들어야 했다.
(대기열 잘 못 만들면 ... 큰일난다)

6차 문제 해결 방법 1: SSE
첫 번째는 SSE였다.
SSE는 서버와의 연결을 유지한 채, 서버가 클라이언트에게 상태 변화를 밀어주는 방식이다.
사용자 입장에서는 별도 요청 없이도 상태가 갱신되기 때문에, 대기열처럼 상태 변화가 중요한 기능에 꽤 잘 어울려 보였다.
특히 처음에는 이런 점이 좋아 보였다.
- 사용자가 계속 새로고침하지 않아도 된다
- 상태가 바뀌는 순간 서버가 바로 알려줄 수 있다
- WebSocket보다는 구조가 단순해 보인다
즉, “대기열에서 내 차례가 오면 서버가 바로 알려주는 구조”라는 점만 보면 꽤 매력적이었다.
하지만 실제 상황에 대입해보니 부담도 분명했다.
가장 큰 문제는 연결을 오래 유지해야 한다는 점이었다.
대기 인원이 많아질수록 서버와 로드밸런서는 그 수만큼의 연결을 오래 붙들고 있어야 한다.
우리가 현재 예상하는 1,500 ~ 2,000명이 동시에 대기열에 들어와 있고, 이 중 상당수가 몇 분씩 WAITING 상태를 유지한다고 생각해보면, 그 연결 자체가 새로운 관리 대상이 된다.
게다가 대기열에서는 모든 사용자에게 실시간으로 많은 이벤트를 보내는 것도 아니다.
대부분의 사용자는 상당 시간 동안 그냥 WAITING 상태에 머물러 있고, 상태 변화는 생각보다 자주 일어나지 않는다.
즉, 연결은 계속 붙잡고 있지만 실제로 자주 보내는 정보는 많지 않은 구조가 된다.
이런 상황에서는 실시간으로 밀어줄 수 있다는 장점보다,
장시간 연결을 유지하는 비용이 더 크게 느껴졌다.
6차 문제 해결 방법 2: WebSocket
두 번째는 WebSocket 이었다.
WebSocket은 양방향 통신이 가능하고, 실시간성이 가장 뛰어난 방식 중 하나다.
서버가 상태를 즉시 밀어줄 수 있을 뿐 아니라, 필요하다면 클라이언트와 더 풍부한 상호작용도 만들 수 있다.
처음에는 이 방식도 상당히 좋아 보였다.
- 가장 실시간에 가까운 방식이고
- 서버가 상태 변화를 즉시 전달할 수 있고
- 이후 더 복잡한 상호작용까지 확장하기 좋다
즉, 실시간 대기열이라는 이미지와 제일 잘 어울리는 방식처럼 느껴졌다.
하지만 이번 이벤트에서 정말 필요한 것을 다시 생각해보니, WebSocket은 다소 과한 선택일 수 있었다.
우리가 필요했던 것은 채팅처럼 양방향 상호작용이 핵심인 시스템이 아니었다.
대부분의 경우 사용자는 지금 내 상태가 무엇인가만 알면 됐고, 서버도 기다리기 or 다음 단계 진행 정도의 정보만 전달하면 충분했다.
즉, WebSocket이 제공하는 강한 양방향성은 유용해보였지만
이번 문제에서는 필수 기능이라기보다 여유 기능에 가까웠다.
운영 측면의 부담도 있었다.
- 연결을 오래 유지해야 하고
- 연결이 끊겼을 때 재연결 전략도 생각해야 하고
- 배포나 일시적인 네트워크 문제 이후 재접속이 한꺼번에 몰릴 가능성도 고려해야 하고
- 애플리케이션 서버 입장에서도 지속 연결을 계속 관리해야 한다
한마디로, WebSocket은 분명 강력했지만
이번 이벤트가 요구하는 수준에 비해 운영 복잡도가 커질 가능성이 있었다.
특히 이번 이벤트는 첫 시도였고,
짧은 기간 안에 안정적으로 붙일 수 있는가가 훨씬 중요했다.
그 관점에서 보면 WebSocket은 “할 수는 있지만 지금 꼭 필요한가?”라는 질문에 선뜻 그렇다고 답할수가 없었다.
6차 문제 해결 방법 3: Polling
세 번째는 Polling 이었다.
Polling은 사용자가 일정 주기마다 서버에 상태를 다시 요청하는 방식이다.
실시간성만 놓고 보면 SSE나 WebSocket보다 덜 세련돼 보일 수 있다.
사용자가 계속 상태가 바뀌었는지를 물어봐야 하기 때문이다.
처음에는 가장 단순한 방식처럼 느껴졌다.
- 구현이 단순하고
- 브라우저와 서버 모두 익숙한 방식이고
- 디버깅이나 운영도 상대적으로 쉽다
하지만 단순하다고 해서 무조건 좋은 것은 아니었다.
Polling도 잘못 쓰면 꽤 위험하다.
예를 들어 대기 중인 사용자가 2,000명인데, 모두가 1초마다 상태를 조회한다고 해보자.
그러면 발급 요청과는 별개로 상태 조회 요청만으로도 초당 2,000건이 추가된다.
즉, 실제 발급 요청은 잘 제어해놓고도 조회 요청 때문에 앞단이 다시 흔들릴 수 있다.
그래서 Polling은 처음부터 “쉽다”는 이유만으로 선택할 수 있는 방식은 아니었다.
중요한 건 그 polling을 얼마나 통제된 형태로 만들 수 있느냐였다.
다만 Polling에는 분명한 장점도 있었다.
Polling은 요청이 들어온 순간에만 자원을 사용하고, 응답을 반환한 뒤에는 연결을 정리할 수 있다.
즉, SSE나 WebSocket처럼 대규모 지속 연결을 오래 유지하지 않아도 된다.
물론 매번 새 연결을 맺는다면 비효율적일 수 있다.
하지만 HTTP keep-alive를 활용하면 같은 연결을 재사용할 수 있어서, 연결 생성 비용을 어느 정도 줄일 수 있다.
즉, Polling은 실시간성에서는 조금 손해를 보더라도,
대규모 대기열 환경에서 지속 연결을 오래 유지하지 않고도 비교적 단순하게 운영할 수 있는 방식이라는 장점이 있었다.
6차 문제 해결
세 가지를 놓고 비교해보니 기준이 조금씩 분명해졌다.
이번 이벤트에서 정말 중요했던 것은
가장 실시간에 가까운 방식이 아니라,
대기열 상태를 사용자에게 충분히 보여주면서도 시스템 전체를 흔들지 않는 방식이었다.
그 관점에서 보면 SSE와 WebSocket은 분명 매력적이었지만,
대기 인원이 많을 때 장시간 연결을 계속 유지해야 한다는 부담이 있었다.
반면 Polling은 덜 세련돼 보일 수는 있어도,
요청이 들어온 순간에만 자원을 사용하고 비교적 단순하게 운영할 수 있다는 점에서 이번 이벤트의 조건에 더 잘 맞았다.
그래서 최종적으로는 Polling 을 선택했다.
다만 여기서 중요한 건,
우리가 선택한 것은 단순한 “고정 주기 폴링”이 아니라는 점이었다.
문제는 폴링을 선택했다고 해서 끝이 아니라는 것이었다.
대기 인원이 많아질수록 상태 조회 요청 자체가 또 다른 트래픽 폭탄이 될 수 있기 때문이다.
그래서 폴링은 허용하되, 조회 주기를 클라이언트에 맡기지 않았다.
대신 서버가 응답에 retryAfterMs 같은 값을 함께 내려주고, 클라이언트는 그 간격에 맞춰 다시 조회하도록 만들었다.
핵심은 조회 빈도까지 서버가 통제하는 것이었다.
대기열 뒤쪽 사용자는 더 긴 간격으로, 앞쪽에 가까워질수록 더 짧은 간격으로 조회하게 해서
상태 조회 요청 자체도 시스템이 감당 가능한 범위 안에서 움직이도록 했다.
예를 들어 뒤쪽 사용자에게는 최대 1분 수준의 간격을 주고,
순번이 앞당겨질수록 그 값을 점차 줄여
앞쪽 사용자에게는 1초 수준으로 짧게 조회하도록 했다.
이 방식이 중요했던 이유는 단순히 현재 상태를 보여주기 위해서가 아니었다.
우리는 상태 조회 요청조차도 전체 시스템 부하 관점에서 통제 가능한 구조를 만들고 싶었다.
결국 이번 이벤트에서는 SSE나 WebSocket이 가진 장점도 분명히 있었지만,
대규모 대기열 상황에서의 연결 유지 비용, 운영 복잡도, 그리고 우리가 실제로 필요로 하는 실시간성 수준을 함께 비교했을 때
가장 현실적인 선택은 서버 주도 폴링 전략이었다.

7차 문제: 실제 발급 구간을 어떻게 제어할 것인가
여기까지 오면 대기열 자체는 어느 정도 정리된 셈이다.
Redis 안에서 요청을 줄 세웠고,
사용자는 WAITING 상태로 관리되며,
자신의 순번과 상태도 폴링을 통해 확인할 수 있게 됐다.
하지만 여기서 끝은 아니었다.
대기열을 잘 만들었다고 해서, 그다음 단계인 실제 발급 구간까지 자동으로 안전해지는 것은 아니기 때문이다.
문제는 단순했다.
“줄을 선 사람들을 어떤 기준으로, 어떤 속도로 실제 발급 단계로 넘길 것인가?”
여기서 가장 경계했던 건 WAITING 상태의 사용자를 한꺼번에 DB로 보내는 구조였다.
애초에 대기열을 만든 이유 자체가 폭주한 요청을 바로 DB로 흘려보내지 않기 위해서였는데, 줄을 세운 뒤 다시 모든 사용자가 동시에 발급을 시도하게 만들면 결국 병목은 다시 DB로 되돌아간다.
즉, 대기열은 만들었지만 실제 경쟁이 일어나는 구간은 여전히 통제되지 않은 상태였던 셈이다.
특히 쿠폰 발급은 단순 조회가 아니다.
실제 발급 단계에 들어오면 캡차 검증이 필요하고, 발급 가능 여부를 다시 확인해야 하고, 최종적으로는 DB에 발급 내역까지 남겨야 한다.
즉, WAITING 상태에서의 조회보다 훨씬 무거운 작업이 뒤따른다.
이 구간에 너무 많은 사용자가 동시에 진입하면, 앞단에서 아무리 대기열을 잘 정리해도 마지막 발급 단계에서 다시 병목이 생길 수 있다.
결국 여기서 내린 결론은 분명했다.
대기열은 전체 요청을 흡수하기 위한 장치였고, 실제 발급 구간은 그중에서도 지금 처리 가능한 만큼만 제한적으로 들어가야 하는 구간이어야 했다.
그래서 WAITING 상태의 사용자 전체를 바로 발급 단계로 보내지 않고, 일부 트래픽만 ACTIVE 상태로 전환해 실제 발급 구간으로 넘기기로 했다.
그런데 여기서도 문제가 완전히 끝난 것은 아니었다.
Redis를 도입해서 DB로 들어오는 트래픽은 획기적으로 줄였지만, 여전히 ACTIVE 상태의 사용자들은 거의 동시에 실제 발급을 시도할 수 있다.
그리고 이 순간에는 결국 같은 쿠폰 자원을 두고 경쟁이 발생한다.
즉, 이제는 질문이 조금 바뀐다.
“ACTIVE로 넘어온 요청들은 DB 안에서 어떻게 안전하게 처리할 것인가?”
처음 떠올린 건 익숙한 동시성 제어 기법들이었다.
7차 문제 해결 방법 1: 비관적 락
비관적 락은 가장 직관적이었다.
먼저 락을 잡고, 다른 요청은 기다리게 만들면 정합성은 강하게 보장할 수 있다.
처음에는 오히려 이 방식이 제일 안전해 보이기도 했다.
“어차피 마지막 발급 단계인데, 확실하게 잠그고 처리하면 되지 않을까?”라는 생각이 들었기 때문이다.
그런데 곰곰이 생각해보니, 비관적 락의 본질은 결국 기다림이었다.
경합이 생기면 뒤의 요청이 다음 발급 가능한 대상을 바로 처리하는 것이 아니라,
앞선 트랜잭션이 락을 놓을 때까지 그대로 기다리게 된다.
즉, 충돌 상황에서 문제를 “없애는” 방식이 아니라,
대기를 통해 순서를 세워 해결하는 방식에 가깝다.
문제는 우리가 이미 앞단에서 WAITING과 ACTIVE를 나눠서,
DB 앞에 너무 많은 요청이 한꺼번에 몰리지 않도록 구조를 바꿔둔 상태였다는 점이다.
그런데 DB 안에서 다시 비관적 락으로 줄을 세우기 시작하면,
앞단에서 힘들게 줄여놓은 경쟁을 마지막 단계에서 또 다른 긴 대기열로 바꾸는 셈이 된다.
특히 선착순 발급에서는 몇 장 남지 않은 상황에서 충돌이 가장 심해진다.
이때 하나의 트랜잭션이 락을 잡고 있는 동안, 뒤의 요청들은 그냥 실패하는 것이 아니라
DB 커넥션을 붙잡은 채 대기하게 된다.
즉, ACTIVE로 넘어온 요청 수를 줄였다고 해도 그 안에서 다시 대기가 길어지면,
커넥션은 빠르게 반환되지 못하고 응답 시간은 점점 길어진다.
이 구조가 무서운 이유는, 비관적 락이 단순히 “한 요청을 잠깐 기다리게 만드는 것”에서 끝나지 않기 때문이다.
대기 중인 트랜잭션은 커넥션을 점유하고, 커넥션이 오래 점유되면 풀은 빠르게 고갈되고, 커넥션을 얻지 못한 뒤 요청들은 애플리케이션 서버에서 다시 대기하고, 그 대기는 다시 스레드 점유와 응답 지연으로 이어진다
즉, 락 경합 하나가 DB 안에서만 머무는 것이 아니라
커넥션 풀 고갈 → 애플리케이션 서버 대기 증가 → 전체 응답 지연으로 이어지는 연쇄 문제로 번질 수 있었다.
여기서 더 걸렸던 건, 비관적 락이 선착순 보장 자체를 깔끔하게 설명해주지도 못한다는 점이었다.
실제 서비스에서는 사용자가 먼저 버튼을 눌렀다는 사실과, 그 요청이 더 먼저 DB 커넥션을 얻고 락 대기열에 진입했다는 사실이 항상 일치하지는 않는다.
요청은 네트워크 지연을 겪고, 로드밸런서를 지나고, 서버에서 스케줄링되고, 커넥션 풀을 기다리는 과정까지 거친다.
즉, 사용자의 체감상 “내가 먼저 눌렀다”와
DB 레벨에서 “내가 먼저 락을 기다리기 시작했다”는 전혀 다른 이야기일 수 있다.
결국 비관적 락은 row 하나의 정합성은 강하게 지켜줄 수 있어도,
우리가 원했던 서비스 전체 관점의 선착순을 자연스럽게 보장해주는 장치는 아니었다.
정리하면, 비관적 락은 안전한 선택처럼 보였지만
실제로는 우리가 이 구조 전체를 통해 줄이고 싶었던 기다림의 비용을 마지막 단계에서 다시 크게 키울 가능성이 있었다.
그리고 그 기다림은 단순한 응답 지연을 넘어,
커넥션 풀 고갈과 전체 시스템 불안정으로 이어질 수 있었다.
7차 문제 해결 방법 2: 낙관적 락
낙관적 락도 처음에는 꽤 괜찮아 보였다.
비관적 락처럼 먼저 row를 붙잡고 기다리게 만드는 방식이 아니라,
일단 읽고 수정한 뒤 충돌이 발생했을 때만 실패로 처리하거나 재시도하면 되기 때문이다.
즉, 락을 오래 잡지 않으니 겉으로 보기에는 더 가볍고, DB 안에서 긴 대기열을 만들지 않는다는 점도 매력적으로 느껴졌다.
특히 우리는 이미 앞단에서 WAITING과 ACTIVE를 나눠 DB로 들어오는 요청 수 자체를 줄여둔 상태였다.
그래서 한때는 “이 정도로 줄여놨다면 낙관적 락으로도 충분하지 않을까?”라는 생각도 했다.
평상시처럼 충돌이 드문 상황이라면, 실제로 이 방식은 꽤 깔끔하게 동작할 수 있다.
하지만 선착순 발급은 낙관적 락이 가장 잘 맞는 상황과는 결이 달랐다.
낙관적 락은 기본적으로 “충돌은 가끔 일어나는 예외적인 상황” 이라는 전제를 깔고 있다.
그런데 선착순 이벤트, 특히 마지막 몇 장을 두고 경쟁하는 구간에서는 충돌이 예외가 아니라 거의 예상된 기본 상황에 가깝다.
예를 들어 ACTIVE 상태의 여러 사용자가 거의 동시에 마지막 쿠폰 몇 장을 두고 발급을 시도한다고 해보자.
이때 먼저 읽은 데이터가 이미 다른 트랜잭션에 의해 바뀌어 있으면,
낙관적 락은 그 요청을 실패시키고 다시 시도하게 만든다.
문제는 이 “다시 시도”가 공짜가 아니라는 점이었다.
한 번 충돌이 나면 끝나는 게 아니라,
다시 읽어야 하고
다시 검증해야 하고
다시 업데이트를 시도해야 한다
즉, 충돌이 많아질수록 요청 하나가 끝날 때까지 거치는 왕복이 늘어난다.
겉으로는 락을 오래 잡지 않아서 가벼워 보이지만,
실제로는 실패와 재시도가 누적되면서 DB에 더 많은 읽기/쓰기 부담을 줄 수 있다.
특히 선착순 이벤트에서는 이 재시도가 더 불편했다.
우리는 앞단에서 힘들게 WAITING과 ACTIVE로 구간을 나눠
DB에 들어오는 경쟁 자체를 줄여놓은 상태였다.
그런데 마지막 단계에서 낙관적 락으로 재시도가 반복되기 시작하면,
앞단에서 줄여놓은 트래픽을 DB 안에서 다시 충돌과 재시도 형태로 되살리는 셈이 된다.
게다가 선착순 관점에서도 마음에 걸리는 지점이 있었다.
낙관적 락은 결국 먼저 성공적으로 커밋한 요청이 이기는 구조에 가깝다.
하지만 사용자의 관점에서 선착순은 “내가 먼저 눌렀는가”에 더 가깝다.
이 둘은 항상 일치하지 않는다.
누군가는 먼저 요청을 보냈더라도 네트워크 지연이나 서버 스케줄링 때문에 재시도가 한 번 더 발생할 수 있고,
반대로 조금 늦게 들어온 요청이 더 빠르게 재시도를 끝내고 먼저 성공할 수도 있다.
즉, 낙관적 락은 정합성은 지킬 수 있어도, 우리가 기대하는 선착순의 체감과는 어긋날 가능성이 있었다.
정리하면, 낙관적 락은
평소처럼 충돌이 적은 상황에서는 가볍고 좋은 선택일 수 있다.
하지만 이번처럼 마지막 순간에 충돌이 집중되는 선착순 이벤트에서는
실패와 재시도가 빠르게 늘어나고, 그 비용이 다시 DB 부담으로 돌아올 수 있었다.
즉, 낙관적 락은
비관적 락처럼 긴 대기를 만들지는 않지만,
대신 충돌을 재시도로 바꿔서 처리하는 방식이었다.
그리고 이번 문제에서는 그 재시도 비용 역시 충분히 부담스러웠다.
7차 문제 해결 방법 3: 원자적 조건 업데이트
원자적 조건 업데이트도 후보였다.
예를 들어 remaining > 0 일 때만 차감하는 방식은 단순하고 빠르다.
비관적 락처럼 기다림을 길게 만들지도 않고, 낙관적 락처럼 실패 후 재시도를 전제로 하지도 않는다는 점에서 꽤 매력적으로 보였다.
하지만 우리 구조를 다시 대입해보니, 이번 문제는 단순한 수량 차감으로만 설명하기 어려웠다.
우리가 정말로 처리해야 했던 것은 remaining 값을 1 줄이는 일이 아니라, 발급 가능한 쿠폰 하나를 특정 사용자에게 확정하는 과정이었기 때문이다.
즉, 원자적 조건 업데이트는
“재고가 남아 있는가”를 판단하고 차감하는 데는 강했지만,
어떤 쿠폰이 누구에게 발급되었는가를 자연스럽게 표현하는 구조와는 조금 결이 달랐다.
결국 이번 문제에는 숫자를 줄이는 방식보다,
실제 발급 가능한 row 하나를 안전하게 가져와 사용자에게 연결하는 방식이 더 잘 맞았다.
7차 문제 해결 방법 4: 스킵 락
스킵 락도 후보였다.
이미 다른 트랜잭션이 잡고 있는 row는 기다리지 않고 건너뛰는 방식이다.
사실 이 방법이 제일 먼저 생갔났고 우리 구조에 대입해보면 가장 잘 맞을 가능성이 커 보였다.
중요한 건 선착순의 질서를 DB에서 처음부터 만들고 있지 않았다는 점이다.
우리는 이미 앞단에서 Redis 대기열을 통해 요청 순서를 정리했고,
WAITING과 ACTIVE로 상태를 나눠서 실제 발급 단계에 들어오는 요청 수까지 줄여둔 상태였다.
즉, DB의 역할은 “누가 먼저인가”를 처음부터 다시 판단하는 것이 아니라,
이미 정리된 경쟁 구간을 빠르게 마무리하는 것에 더 가까웠다.
특히 우리는 쿠폰을 단순한 숫자 재고가 아니라, 미발급 상태의 row 집합으로 보고 있었다.
즉, 실제 발급 시점에는 그중 아직 아무에게도 할당되지 않은 row 하나를 가져와 사용자에게 연결하는 구조였다.
이렇게 보면 문제는 remaining 값을 1 줄이는 것이 아니다.
핵심은 발급 가능한 쿠폰 row 하나를 지금 이 사용자에게 안전하게 확정할 수 있는가였다.
이때 비관적 락처럼 하나의 row 앞에서 기다리게 만들면, 결국 뒤의 요청들은 커넥션을 붙잡은 채 대기하게 된다.
반대로 스킵 락은 이미 다른 트랜잭션이 잡고 있는 row를 기다리지 않고, 다음으로 발급 가능한 row를 바로 찾게 만든다.
즉, 이 방식의 장점은 분명했다.
- 락은 사용하되 긴 대기를 만들지 않고
- 여러 트랜잭션이 동시에 들어와도 서로 다른 쿠폰 row를 병렬로 가져갈 수 있고
- 앞단에서 줄여놓은 ACTIVE 경쟁 구간을 DB 안에서 짧고 빠르게 끝낼 수 있다
결국 스킵 락은
이미 정리된 질서를 DB 안에서 대기 없이 확정하는 도구에 더 가까웠다.
7차 해결 : 결국 스킵 락이 가장 잘 맞았다
여기까지 비교해보니 기준이 조금씩 분명해졌다.
- 비관적 락은 안전하지만 기다림이 길어진다
- 낙관적 락은 가볍지만 충돌이 많아지면 실패와 재시도 비용이 커진다
- 원자적 조건 업데이트는 재고 차감에는 좋지만, 개별 발급 대상을 확정하는 흐름과는 조금 어긋난다
반면 스킵 락은 우리 구조와 잘 맞았다.
여기서 중요한 건 다시 한 번, 선착순의 질서를 DB가 처음부터 만들고 있지 않았다는 점이다.
우리는 이미 Redis 대기열에서 순서를 정리했고, WAITING과 ACTIVE를 나눠 실제 발급 단계로 들어오는 요청 수도 제한해둔 상태였다.
즉, DB의 역할은 “누가 먼저인가”를 다시 판정하는 것이 아니라, 이미 줄어든 경쟁 구간을 빠르게 확정하는 것이었다.
이게 중요했다.
비관적 락처럼 기다리게 만들면 ACTIVE로 들어온 요청들조차 다시 DB 안에서 줄을 서게 된다.
그 기다림은 곧 커넥션 점유 시간 증가로 이어지고, 응답 지연과 풀 고갈 위험도 다시 커진다.
앞단에서 어렵게 줄여놓은 경쟁을 마지막 단계에서 다시 대기열로 바꾸는 셈이다.
반면 스킵 락은 락을 사용하되 대기를 최소화한다.
이미 잠긴 row는 기다리지 않고 건너뛰기 때문에, 여러 트랜잭션이 동시에 들어와도 서로 다른 쿠폰 row를 병렬로 확정할 수 있다.
즉, 우리 구조에서 스킵 락은
선착순의 질서를 만드는 도구라기보다, 이미 정리된 질서를 DB 안에서 빠르게 마무리하는 도구에 더 가까웠다.
물론 이것만으로 모든 문제가 끝나는 것은 아니었다.
같은 사용자가 여러 번 발급을 시도하는 문제는 락만으로 막을 수 없었다.
그래서 마지막 안전장치로 (event_id, member_id) 같은 UNIQUE 제약도 함께 두었다.
정리하면 역할은 이렇게 나뉜다.
- WAITING / ACTIVE: 앞단에서 전체 경쟁을 줄인다
- SKIP LOCKED: DB 안에서 발급 가능한 쿠폰 row를 빠르게 확정한다
- UNIQUE 제약: 같은 사용자의 중복 발급을 마지막으로 차단한다
결국 우리가 원했던 건 모든 요청을 강한 락으로 세워놓는 구조가 아니었다.
앞단에서는 경쟁 자체를 줄이고, DB 안에서는 이미 줄어든 경쟁을 짧고 빠르게 확정하는 구조가 더 잘 맞았다.
그 기준에서 봤을 때, 최종 선택은 스킵 락이 가장 자연스러웠다.
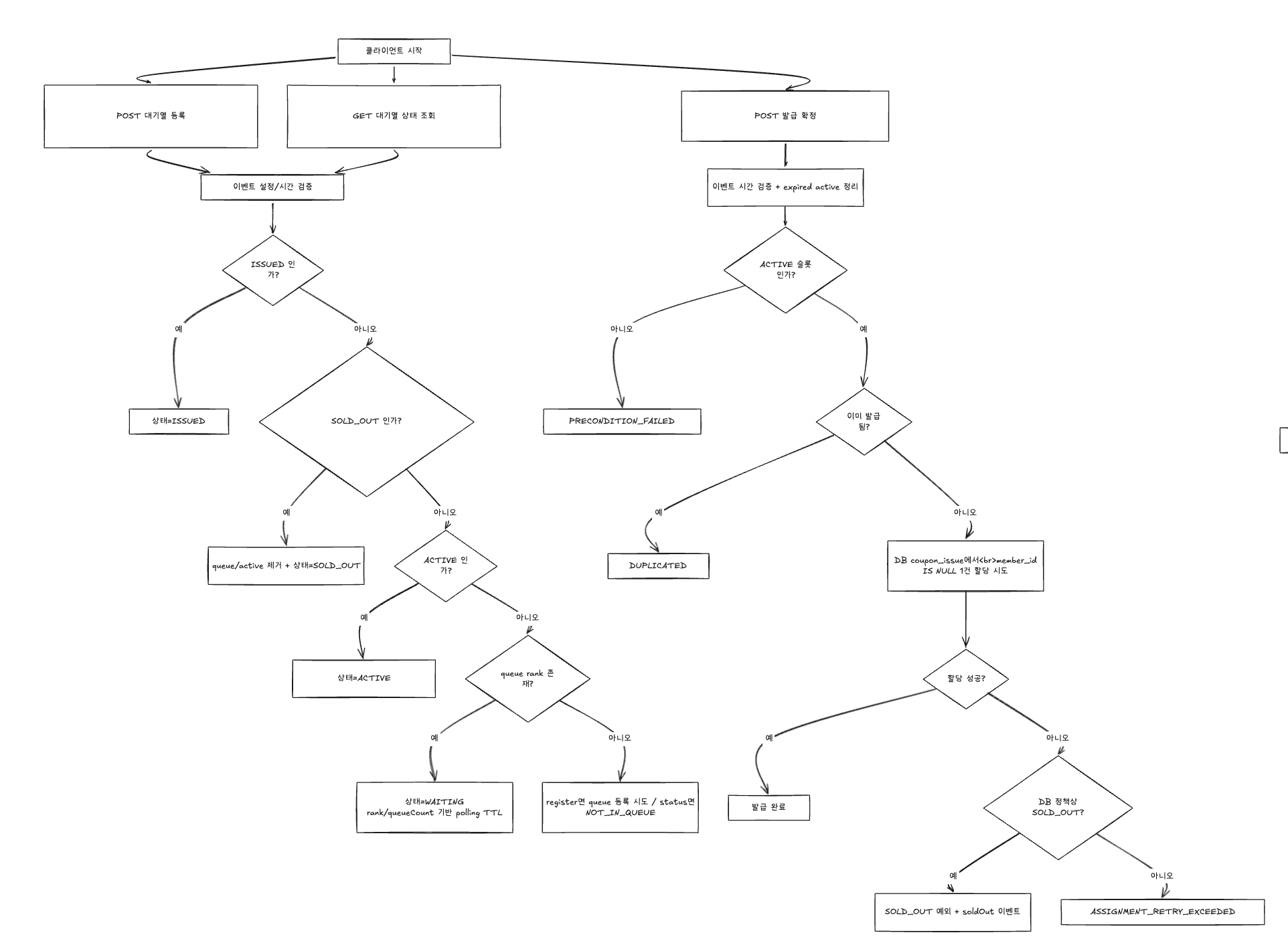
최종 설계

부하테스트
첫 부하 테스트: “짧은 순간의 폭주”를 버틸 수 있는지부터 확인
첫 부하 테스트는 N명의 가상 유저가 한 번씩만 요청을 보내는 방식으로 잡았다.
선착순 이벤트는 일반적인 API처럼 꾸준히 많은 요청이 들어오는 상황과는 조금 다르다.
결국 중요한 건 처음 등록하는 그 순간, 아주 짧은 시간 안에 요청이 한꺼번에 몰렸을 때 버틸 수 있느냐였다.
그래서 테스트도 그 특성에 맞춰, 지속 부하보다는 순간적인 버스트 트래픽을 재현하는 쪽으로 시작했다.
첫 테스트 한계점을 알기위해 일부러 크게 잡아서 가상 유저 5,000명, 서버 2대로 진행했다.



결과는 기대와는 꽤 거리가 있었다.
우선 p90이 5초대로 너무 느렸다.
TPS도 742 수준으로 낮게 나왔다.
또한 연결 구간에서 시간이 꽤 많이 소요되고 있었다.
즉, 단순히 비즈니스 로직만 느린 게 아니라,
연결 자체도 느리고 서버 처리도 느린 상태였다.
일단 비즈니스 로직이 왜 느린지 부터 점검해보았다.
병목 원인 1: 대기열 API가 세션 DB를 타고 있었다
원인을 확인해보니 생각보다 단순하면서도 치명적인 문제가 있었다.
이벤트 API에만 집중하고 있다보니 세션을 생각하지 못했다.
우리 서비스는 분산 서버 환경이라 세션 로그인 방식을 사용하고 있었고,
로그인 세션 정보는 세션 DB에 저장하고 있었다.
즉, 대기열 관련 API를 아주 짧게 조회하는 순간에도
매번 세션 저장소를 거치고 있었던 것이다.
선착순 이벤트에서는 이런 짧은 조회가 매우 자주 일어난다.
그런데 매 요청마다 세션 DB를 한 번씩 건드리고 있었다면,
대기열 API는 시작부터 불필요한 DB 비용을 안고 있었던 셈이다.
결국 대기열 관련 API만큼은 기존 세션 로그인 방식과는 다르게 가져가기로 했다.
즉, 이벤트 API에서 세션 DB 의존을 제거하는 방향으로 바꿨다.
1차 개선 이후: 시간은 절반 가까이 줄었다.
세션 DB를 완전히 제거한 뒤 다시 같은 조건으로 테스트를 해봤다.



확실히 효과는 있었다.
전체 응답 시간은 이전보다 절반 가까이 줄었다.
즉, 처음 병목 중 하나였던 불필요한 DB 접근은 분명히 제거된 것이다.
병목 원인 2: 왕복 횟수
더 개선할 수 있는 방법이 있는지 찾아보다가, 내가 의심한 병목은 복잡한 비즈니스 로직 그 자체보다는 Redis 왕복 횟수였다.
대기열 등록과 조회 요청 하나를 처리하는 동안 Redis에 여러 번 왕복하고 있었고,
오픈 시점처럼 짧은 시간에 요청이 몰리는 상황에서는 이 작은 왕복 비용이 그대로 지연으로 누적될 수 있었다.
결국 핵심은 비즈니스 로직을 바꾸는 것이 아니라,
같은 정보를 더 적은 네트워크 왕복으로 읽도록 바꾸는 것이라고 봤다.
문제: 요청 하나가 Redis를 너무 자주 왕복하고 있었다
대기열 등록 API는 단순히 사용자를 queue에 넣는 작업으로 끝나지 않는다.
요청을 처리하려면 현재 사용자가 어떤 상태인지 먼저 확인해야 한다.
예를 들면 아래 정보들이 필요하다.
- 이미 발급을 받은 사용자인지
- 현재 sold out 상태인지
- 이미 active 상태인지
- 이미 queue에 들어가 있는지
- queue에서 몇 번째인지
- active 인원이 몇 명인지
- queue 전체 인원이 몇 명인지
기존 구조에서는 이런 상태를 각각 개별 메서드로 조회하는 방식에 가까웠다. 개념적으로는 아래와 같은 형태였다.
long activeCount = getActiveCount(couponName);
boolean issued = isIssued(couponName, memberId);
boolean soldOut = isSoldOut(couponName);
Long activeExpireAt = getActiveExpireAtMillis(couponName, memberId);
Long queueRank = rankQueue(couponName, memberId);
long queueCount = getQueueCount(couponName);
각 메서드는 Redis 기준으로 보면 ZCARD, SISMEMBER, GET, ZSCORE, ZRANK 같은 가벼운 명령이다.
문제는 명령이 무겁다는 것이 아니라, 상태를 잘게 나누어 조회하면서 요청 하나가 Redis와 여러 번 왕복하게 된다는 점이었다.
왜 이게 선착순 이벤트에서 더 치명적일까
선착순 이벤트는 일반적인 CRUD API와 다르다.
사용자가 고르게 들어오지 않고, 아주 짧은 시간에 요청이 한꺼번에 몰린다.
이런 상황에서는 평균 응답시간보다 p95, p99 같은 tail latency가 더 중요해진다.
몇 개의 요청이 조금 느린 정도로 끝나는 것이 아니라, 느려진 요청이 뒤쪽 요청들을 밀어내면서 전체 구간의 체감 성능을 급격히 무너뜨릴 수 있기 때문이다.
단건 요청만 보면 Redis 왕복 한두 번 차이는 작아 보일 수 있다.
한 번 조회하는 데 걸리는 시간 자체는 짧고, 로컬 캐시나 메모리 접근과 비교하지 않는 이상 충분히 빠른 편이기도 하다.
하지만 선착순 이벤트처럼 같은 시점에 수천, 수만 건의 요청이 몰리면 이야기가 달라진다.
요청 하나가 Redis를 여러 번 오갈수록 다음과 같은 문제가 생긴다.
- 네트워크 왕복 횟수 자체가 늘어난다.
- Redis 커넥션을 점유하는 시간이 길어진다.
- 애플리케이션 스레드가 응답을 기다리는 시간도 함께 늘어난다.
- 그 결과 동시에 처리할 수 있는 요청 수가 줄어든다.
- 밀린 요청들은 다시 tail latency를 키운다.
특히 선착순 이벤트에서는 이 문제가 더 치명적이다.
이벤트 시작 직후에는 모든 사용자가 거의 동시에 상태를 확인하려고 들어온다.
이때 요청 하나당 Redis 왕복이 1번인 구조와 3번인 구조는, 같은 트래픽이라도 Redis와 애플리케이션이 감당해야 하는 총 작업량이 완전히 달라진다.
예를 들어 초당 5,000개의 요청이 들어오는 상황이라면,
요청당 Redis 왕복이 1번일 때는 초당 5,000번의 왕복이 발생하지만
요청당 3번 왕복하면 초당 15,000번의 왕복이 필요해진다.
이 차이는 단순히 2번 더 조회했다에서 끝나지 않는다.
커넥션 풀 경쟁, 스레드 대기, 응답 지연, 재시도 증가까지 연쇄적으로 이어질 수 있다.
그리고 선착순 시스템에서는 바로 이런 작은 지연이 공정성 문제와 실패율 증가로 이어진다.
결국 이 구간에서는
조회 한 번이 얼마나 빠른가보다
요청 하나를 끝내기 위해 Redis를 몇 번 오가야 하는가가 더 중요하다고 봤다.
개선 방향: 상태 조회를 pipeline으로 묶자
이 문제를 해결하기 위해 상태 조회를 의미 단위로 묶었다.
public QueuePreState getQueuePreState(String couponName, Long memberId) {
List<Object> results = redisTemplate.executePipelined(
new SessionCallback<Object>() {
@Override
public Object execute(RedisOperations operations) {
operations.opsForZSet().zCard(activeKey(couponName));
operations.opsForSet().isMember(issuedKey(couponName), memberId.toString());
operations.opsForValue().get(soldOutKey(couponName));
operations.opsForZSet().score(activeKey(couponName), memberId.toString());
operations.opsForZSet().rank(queueKey(couponName), memberId.toString());
operations.opsForZSet().zCard(queueKey(couponName));
return null;
}
}
);
long activeCount = asLong(results.get(0));
boolean isIssued = asBoolean(results.get(1));
boolean isSoldOut = "1".equals(asText(results.get(2)));
Long activeExpireAt = asLong(results.get(3));
Long rank = asLong(results.get(4));
long queueCount = asLong(results.get(5));
return new QueuePreState(activeCount, isIssued, isSoldOut, activeExpireAt, rank, queueCount);
}핵심은 조회하는 값이 줄어든 게 아니었다.
같은 조회를 더 적은 왕복으로 처리하게 바꿨다는 점이 중요했다.
이전 방식이 아래와 같았다면,
질문 1 -> 응답
질문 2 -> 응답
질문 3 -> 응답
질문 4 -> 응답
질문 5 -> 응답
질문 6 -> 응답
지금 방식은 이렇게 바뀐 셈이다.
질문 1,2,3,4,5,6 한 번에 전송 -> 결과 한 번에 수신
즉 이번 개선의 본질은 "상태를 덜 읽는 것"이 아니라, "같은 상태를 덜 왕복하며 읽는 것"이었다.
2차 개선 이후


실제 5,000 VU 기준 부하 테스트에서도 응답 지표 개선이 확인됐다.
개선 전에는 처리량이 516 req/s 수준이었고, 평균 응답시간은 3.02s 정도였다.
Redis 왕복을 줄인 이후에는 처리량이 871 req/s 수준까지 올라갔고, 평균 응답시간도 2.26s 정도로 줄어들었다.
즉, 같은 구조 안에서 요청당 Redis 왕복 패턴만 줄였는데도 처리량과 응답시간이 모두 눈에 띄게 좋아졌다.
Redis 왕복 최적화가 직접 줄이는 것은 요청 내부의 상태 조회 오버헤드다.
그리고 그 변화가 누적되면서
- 요청당 Redis 대기 시간 감소
- 동시 요청 시 커넥션 점유 시간 감소
- 애플리케이션 스레드 대기 감소
- burst 상황에서의 tail latency 완화
- 결과적으로 처리량 증가
로 이어질 수 있었다.
물론 여기서 조심할 점도 있다.
모든 지표 개선을 Redis 최적화 하나만의 효과로 단정할 수는 없다.
실제 부하 테스트에는 연결 상태, 스레드 상태, 서버 부하 등 여러 요소가 함께 영향을 준다.
다만 적어도 이번 테스트는 한 가지는 분명히 보여줬다.
선착순 이벤트에서는 Redis가 빠르다는 사실만으로는 부족하고, Redis를 어떤 패턴으로 읽고 쓰느냐가 전체 응답 성능에 직접적인 영향을 준다는 점이다.
본격적인 부하 테스트: 현재 구조에서 어디까지 버틸 수 있는가

이후에는 1분 동안 일정한 TPS를 유지하는 방식으로 테스트를 진행했다.
조건은 다음과 같았다.
- 서버 2대
- 톰캣 스레드 MAX 150개
- 목표 TPS를 점진적으로 올려가며 측정
TPS 2,000



이 구간에서는 꽤 안정적이었다.
- p90 33.85ms
응답 시간도 충분히 짧았고 CPU도 3%이하로 사용했다.
현재 구조로는 이 정도 트래픽까지는 큰 무리 없이 처리할 수 있겠다는 느낌이 들었다.
즉, 최소한 2,000 TPS 구간은 안정권으로 볼 수 있었다.
TPS 2,500
다음으로 TPS 2,500을 시도했다.
여기서부터는 분위기가 달라졌다.



- p90 345.62ms
불과 500 TPS 차이인데도,
p90 응답 시간은 거의 10배 이상 느려졌다.
CPU 사용률도 20%로 확 뛰었다.
평균값만 보면 아직 버티는 것처럼 보일 수 있지만,
상위 구간 응답 시간이 급격히 튀기 시작했다는 건
시스템이 슬슬 여유를 잃고 있다는 뜻에 더 가깝다.
즉, TPS 2,500부터는 “된다”가 아니라 “버티긴 버티지만 힘들어한다”는 느낌이 강했다.
TPS 2,800
마지막으로 TPS 2,800도 시도해봤다.
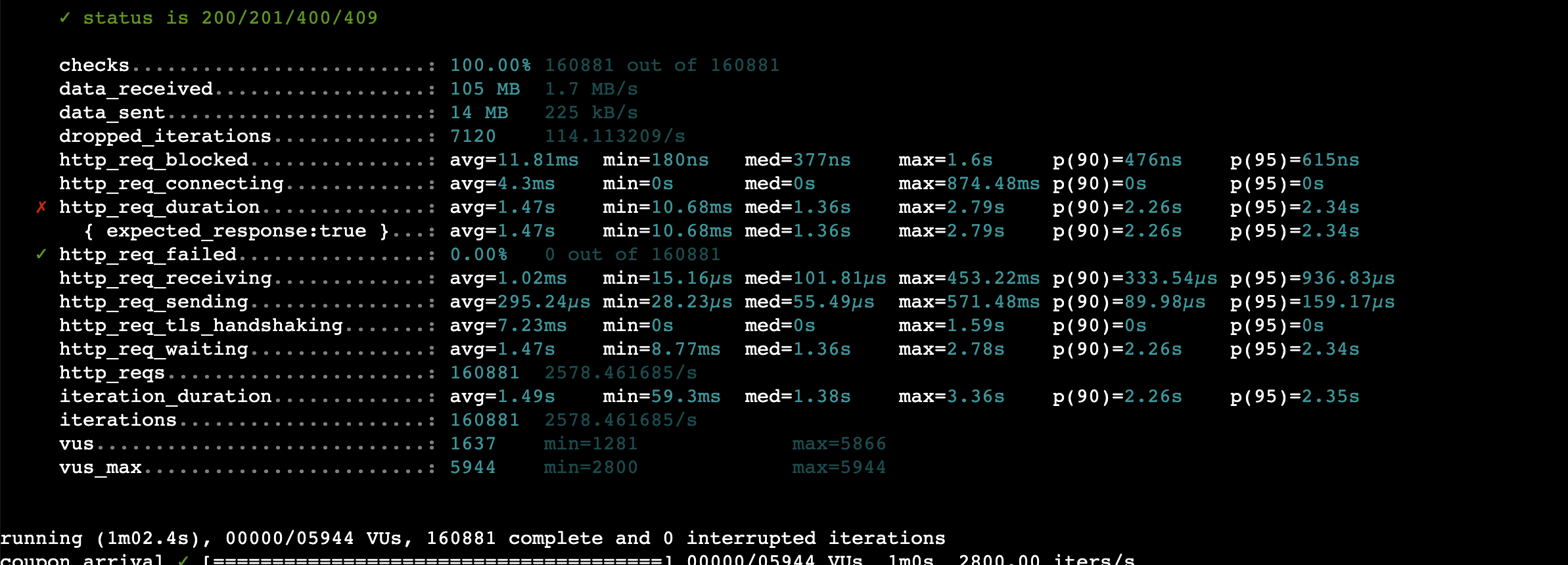


- P90 2.26s
결과적으로는 목표한 2,800 TPS를 온전히 처리하지 못했고,
실제 처리량은 약 2,600 TPS 수준에서 수렴했다.
이 구간에서는 응답 시간도 크게 늘었고,
드롭된 요청도 발생하기 시작했다.
Load Average 역시 올라가면서,
이제는 시스템이 명확하게 포화 구간에 들어섰다는 게 보였다.
CPU 사용률도 50%에 육박했다.
즉, 이 테스트는 꽤 명확했다.
지금 구조에서의 한계는 2,600 TPS 전후로 보였고,
안정적으로 운영 가능한 구간은 2,200TPS 정도였다.
정리: 현재 서버 2대 기준 안정권은 약 2,100 TPS 수준으로 봤다
결과를 종합해보면 이렇다.
- 2,000 TPS: 안정적
- 2,500 TPS: 응답 지연이 눈에 띄게 커지기 시작
- 2,800 TPS 시도: 실제 처리량은 2,600 TPS 수준에서 한계
즉, 현재 서버 2대 구성에서는
약 2,200 TPS 전후가 현실적인 안정권이라고 판단했다.
2,500 TPS부터는 분명히 버거워하는 신호가 보였고,
2,800 TPS에서는 사실상 한계가 드러났다.
이 이상으로 밀어붙이면 “된다”기보다
언제든 흔들릴 수 있는 구간에 가깝다고 봤다.
여기서 조금 더 개선해볼 수 있을까해서 몇 가지 더 고민해보았다.
1. 스레드 설정
가장 먼저 본 건 스레드였다.
순간적으로 요청이 확 몰리는 구조다 보니, 처음에는 스레드 수가 부족해서 병목이 생기는 것 아닐까 싶었다.
그런데 지표를 같이 보면 조금 다르게 보였다.
TPS를 올릴수록 CPU 사용률이 같이 올라가고, 동시에 p90 / p95도 함께 나빠졌다.
즉, 단순히 “스레드가 부족해서 대기만 늘어나는 상황”이라기보다,
서버 한 대가 실제로 감당할 수 있는 처리 한계에 가까워지고 있었다고 보는 편이 더 자연스러웠다.
스레드 문제가 핵심이라면 CPU는 상대적으로 덜 쓰면서 대기만 길어지는 그림이 먼저 보일 수도 있는데,
지금은 처리량이 올라갈수록 CPU와 응답 지표가 함께 무너지는 쪽에 가까웠다.
그래서 이 시점에서는 스레드 수를 무작정 늘리는 것이 근본적인 해결책은 아닐 수 있다고 판단했다.
오히려 그 경우, 더 많은 요청을 동시에 붙잡고 있다가 tail latency만 더 나빠질 가능성도 있었다.
실제로 더 높여보았는데 훨씬 더 성능이 안 좋아졌다.
스레드 max를 170으로 20을 더 높여보았는데 p90/p95는 폭증하고 CPU도 사용률이 10% 더 늘었다.

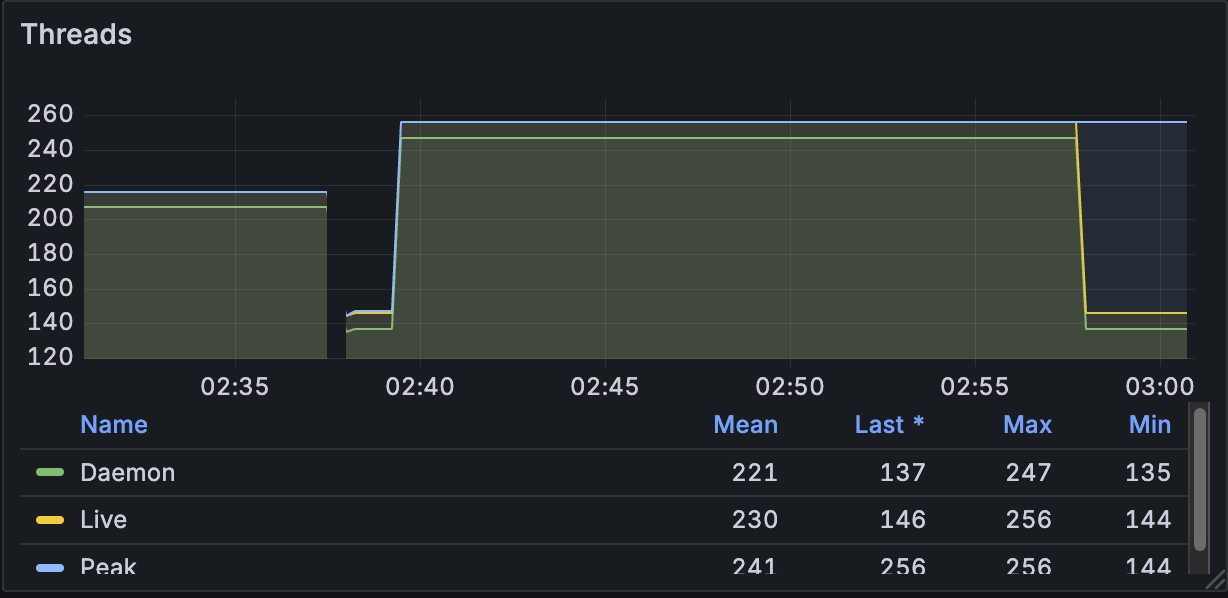

2. Redis 쪽도 더 줄일 수 있는지 다시 봤다
다음으로는 Redis 쪽을 다시 봤다.
혹시 요청당 Redis 명령이 불필요하게 많지는 않은지,
조금이라도 더 줄일 수 있는 부분이 없는지 다시 점검했다.
하지만 이미 Redis 쪽은 꽤 단순하게 가져간 상태였다.
필요한 최소한의 명령만 사용하고 있었고, 구조적으로도 더 크게 덜어낼 만한 부분은 많지 않았다.
즉, 애플리케이션 레벨에서 줄일 수 있는 비용은 이미 한 번 많이 걷어낸 상태였고,
여기서 추가 최적화를 한다고 해도 TPS를 큰 폭으로 더 끌어올릴 수 있을 만큼의 여지는 크지 않아 보였다.
결론
스레드도 먼저 의심해봤고,
Redis 쪽도 다시 점검해봤지만,
결국 지금 한계는 코드 몇 줄 더 줄이거나 설정 하나 바꾼다고 해결될 문제라기보다, 서버 한 대가 감당할 수 있는 물리적인 처리량에 가까워 보였다.
즉, 이 시점에서 더 안정적으로 TPS를 올리려면 수평 확장 쪽으로 가는 것이 가장 현실적인 선택지에 가까웠다.
한 대가 감당해야 하는 TPS를 낮추고, 같은 구조를 여러 대로 분산해서 받는 것.
적어도 현재 테스트 결과만 놓고 보면, 그게 가장 직접적이고 예측 가능한 다음 단계였다.
실제 이벤트에서는 ?
봄봄 선착순 이벤트는 2026년 2월 23일 오후 2시에 진행되었다.
다행히 아무 문제 없이 무사히 잘 마쳤다.




예상보다는 많이 적지만 총 179+분 정도가 참여해주셨고 피크 5분간 총 요청은 9k, 피크 RPM 550, p90 67ms, 에러 0건으로 잘 마무리 될 수 있었다.
성과로는 회원수 300+이 늘었다.
설날도 반납하면서 3주간 열심히 고민하고 기획/설계/구현을 했는데 큰 문제없이 마무리되어서 다행이다.
구현하면서 생각할것도 많아서 배워가는 것도 참 많은 기회였다.
(이벤트 구현도 중요하지말 알리는게 더 어렵다는걸 이번에 알게되었다)
Reference
'서비스 운영 일지 > 봄봄' 카테고리의 다른 글
| 봄봄 코드 리뷰 문화 개선 (5) | 2025.12.23 |
|---|---|
| 이메일 수신 서버 구축 및 뉴스레터 적재 파이프라인 고도화 (1) | 2025.12.14 |
| 봄봄 AWS 비용 다이어트 이야기 (3) | 2025.12.09 |
| 봄봄에서 서드파티 라이브러리를 대하는 방법 (2) | 2025.11.22 |
| 봄봄 서비스에 맞게 검색 성능 개선기 (4) | 2025.11.17 |